BMLang实现的运行效率主要受BMCompiler优化和BMLang编程质量两个方面的影响。 BMCompiler是SOPHGO研发的编译器,会随着版本的更新迭代持续优化性能。 而用户可以操控的是BMLang编程的质量。
要实现能获得高性能的BMLang编程,需要考虑SOPHON TPU架构和BMCompiler编译优化策略。 以下将从多个方面来说明如何实现高质量的BMLang程序。
使用尽可能少的操作¶
当我们考虑用BMLang实现某个算法时,首先需要考虑如何尽可能使用少的BMLang操作来完成计算。 这也是C/C++等其它编程语言的要求,实现尽可能简洁。
让数据访问只发生在本地存储¶
下面是SOPHON TPU的架构简图。
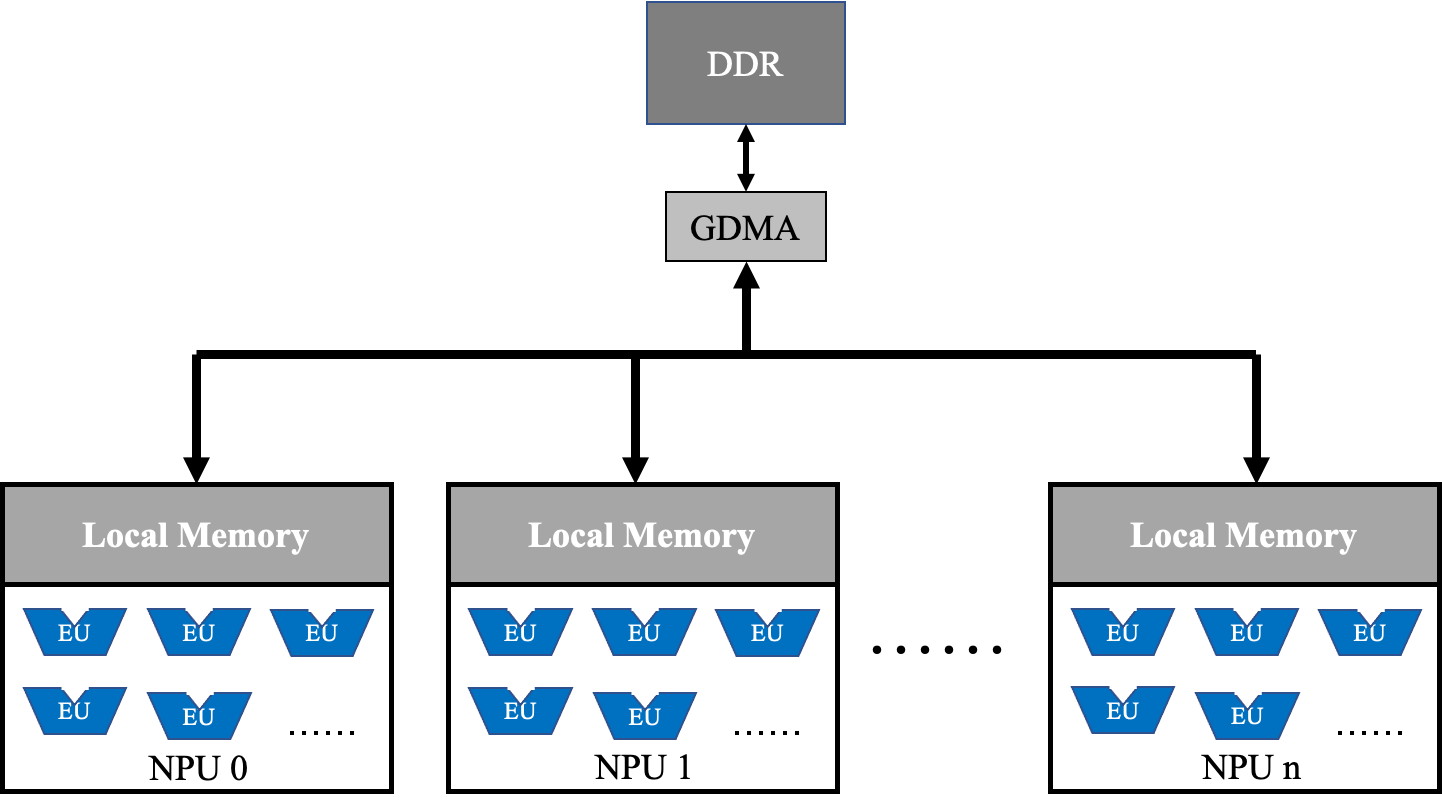
SOPHON TPU是一种众核架构,每个核称作一个神经网络处理单元(NPU),NPU中有一个独立的本地存储和很多个计算单元。 所有NPU以单指令多数据(SIMD)的方式来完成一个计算操作,数据需要通过GDMA从DDR中搬入到NPU的本地存储(Local Memory)才能被EU访问本计算。
因此尽可能减少数据在DDR与本地存储之间的搬运,让计算操作之间对数据的访问只发生在本地存储才能有效的发挥TPU性能。
而BMCompiler编译可以将无限多个连续的BMLang 本地操作 融合在一起,让这些计算操作的数据只返回到本地存储后就直接进入下一个计算操作。
所以,以下编程建议可以获得更好的性能:
尽量少使用 全局操作 。
集中且连续的使用 本地操作 来完成计算。
编程中相邻 本地操作 尽可能是生产者消费者关系。
虽然BMCompiler会有算子重排序等优化策略来优化各种编程可能,但是好的BMLang编程能避免编译器疏忽的优化点。
Tensor数据排布和TPU计算单元使用率¶
BMLang编程过程中所指定的Tensor shape会直接影响到最终的Runtime性能。
首先我们来看下SOPHON TPU架构和数据排布。如下图所示:
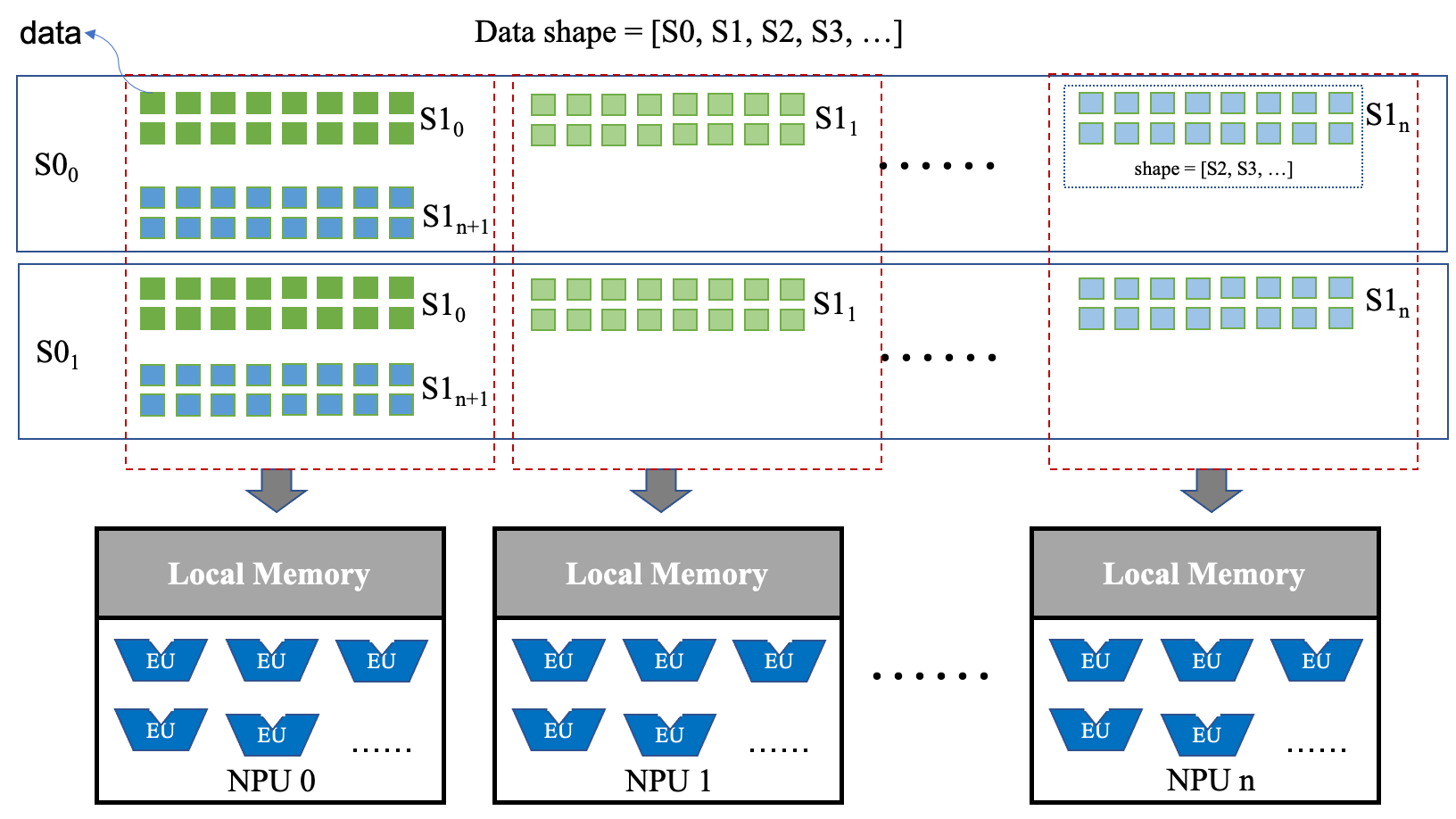
上图中,TPU包含n个神经网络处理单元(NPU),每个NPU又包含多个计算单元(EU)。 n个NPU以单指令多数据(SIMD)的形式运行,所以需要数据并行才能充分利用TPU中的所有EU。
而数据在TPU中的排布方式为:
数据以S1分布在不同的NPU中。
例如:S1:sub: 0所对应的S0、S2、S3…等维度的数据都放在NPU0, S1:sub: x所对应的S0、S2、S3…等维度的数据则放在(x % n)号NPU中。
所以S1需要尽量大于或等于n,这样才能尽可能的把每个NPU利用起来。
BM1682:n等于64。 BM1684:n等于64。
每个NPU中的数据对EU的利用率则看S0、S2、S3… 。
BM1682:NPU一次只能处理S0中的一个单元,所以要想充分的利用NPU的所有EU,S2*S3*…的乘积需要不小于NPU中EU的数量, BM1682每个NPU的EU数量为32。
BM1684:FLOAT32计算时,情况同BM1682,也需要S2*S3*…的乘积需要不小于NPU中EU的数量,只不过BM1684中每个NPU的FLOAT32 EU 数量是16。INT16/UINT16计算时,每个NPU的16bit EU共32个,需要S0至少为2,S2*S3*…的乘积至少为16才能把所有EU给利用起来。 INT8/UINT8计算时,每个NPU的8bit EU共64个,需要S0至少为4,S2*S3*…的乘积至少为16才能把所有EU给利用起来。
注意:以上shape要求主要针对 本地操作 ,全局操作通常没有此限制。
使能数据切分优化¶
BMCompiler编译器在融合本地操作时,会将大数据进行切分,从而保证数据能在本地存储中放得下。
目前BMCompiler融合本地操作时支持S0、S2维度的数据切分,S3维度的数据切分目前只在静态编译下支持,动态编译还未支持。
另外,若本地操作的shape大于4维时,BMCompiler也不能进行融合优化。
所以,尽量设置shape不大于4维,若数据很大,在设置shape时优先将大数设置在S2维度,其次S0维度。