2. 基础概念常见问题¶
2.1. 算丰系列产品有哪些硬件形态?¶
答:芯片BM1684、模组SM5、边缘计算盒子SE5、PCIe加速卡SC5H/SC5+、服务器SG6。
2.2. BM1684中的设备内存?¶
内存是BM1684应用调试中经常会涉及的重要概念,特别地,有以下3个概念需要特别区分清楚:Global Memory、Host Memory、Device Memory。
全局内存(Global Memory): 指BM1684的片外存储DDR,通常为12GB,最大支持定制为16GB。PCIe模式:4GB TPU专用 + 4GB VPU专用 + 4GB VPP/A53专用;SoC模式:4GB A53专用 + 4GB TPU专用 + 4GB VPP/VPU专用。
设备内存(Device Memory)和系统内存(Host Memory): 根据BM168x产品类型或工作模式的不同,设备内存和系统内存具有不同的含义:
SoC模式(SE5) Host Memory是芯片上主控Cortex A53的内存 Device Memory是划分给TPU/VPP/VPU的设备内存
PCIe模式(SC5/SM5) Host Memory是主机的内存 Device Memory是PCIe板卡的设备内存
CModel模式:SophonSDK中提供的BM1684软件模拟器环境,可在没有TPU硬件的情况下,验证模型转换编译
2.2.1. SoC内存映射分区表¶

2.2.2. 各个内存间数据搬运速度说明¶
系统内共有三个内存分别为DDR0-DDR2, 其中DDR0 是交错的。 各个子系统访问规则如下:
jpu |
decode |
encode |
vpp |
gdma |
|
|---|---|---|---|---|---|
DDR0 |
可读写 |
不能访问 |
不能访问 |
可写 |
可读写 |
DDR1 |
可读写 |
可读写 |
可读写 |
可读写 |
可读写 |
DDR2 |
可读写 |
可读写 |
可读写 |
可读写 |
可读写 |
DDR0 的速度最快,DDR1-DDR2 次之,速度排列大致如下:
源 |
目的 |
速度 |
|---|---|---|
DDR0 |
DDR0 |
快 |
DDR0 |
DDR1 |
快 |
DDR0 |
DDR2 |
快 |
DDR1 |
DDR1 |
慢 |
DDR1 |
DDR2 |
快 |
DDR2 |
DDR2 |
慢 |
DDR 到TPU(Local mem)速度分析
源 |
目的 |
速度 |
|---|---|---|
DDR0 |
Local mem |
最快 |
DDR1 |
Local mem |
快 |
DDR2 |
Local mem |
快 |
SOC 下内存带宽速度参考数据如下:
./test_ddr_bindwidth 0x800000
Src:(addr=105100000, heap_id=0), Dst:(addr=105900000,heap_id=0), size:0x800000 byte.
Cost time:633 us, Bandwidth:12638.23 MB/s
Src:(addr=105100000, heap_id=0), Dst:(addr=440000000,heap_id=1), size:0x800000 byte.
Cost time:598 us, Bandwidth:13377.93 MB/s
Src:(addr=440000000, heap_id=1), Dst:(addr=105100000,heap_id=0), size:0x800000 byte.
Cost time:601 us, Bandwidth:13311.15 MB/s
Src:(addr=440000000, heap_id=1), Dst:(addr=440800000,heap_id=1), size:0x800000 byte.
Cost time:1264 us, Bandwidth:6329.11 MB/
2.3. BM1684的基本架构?¶
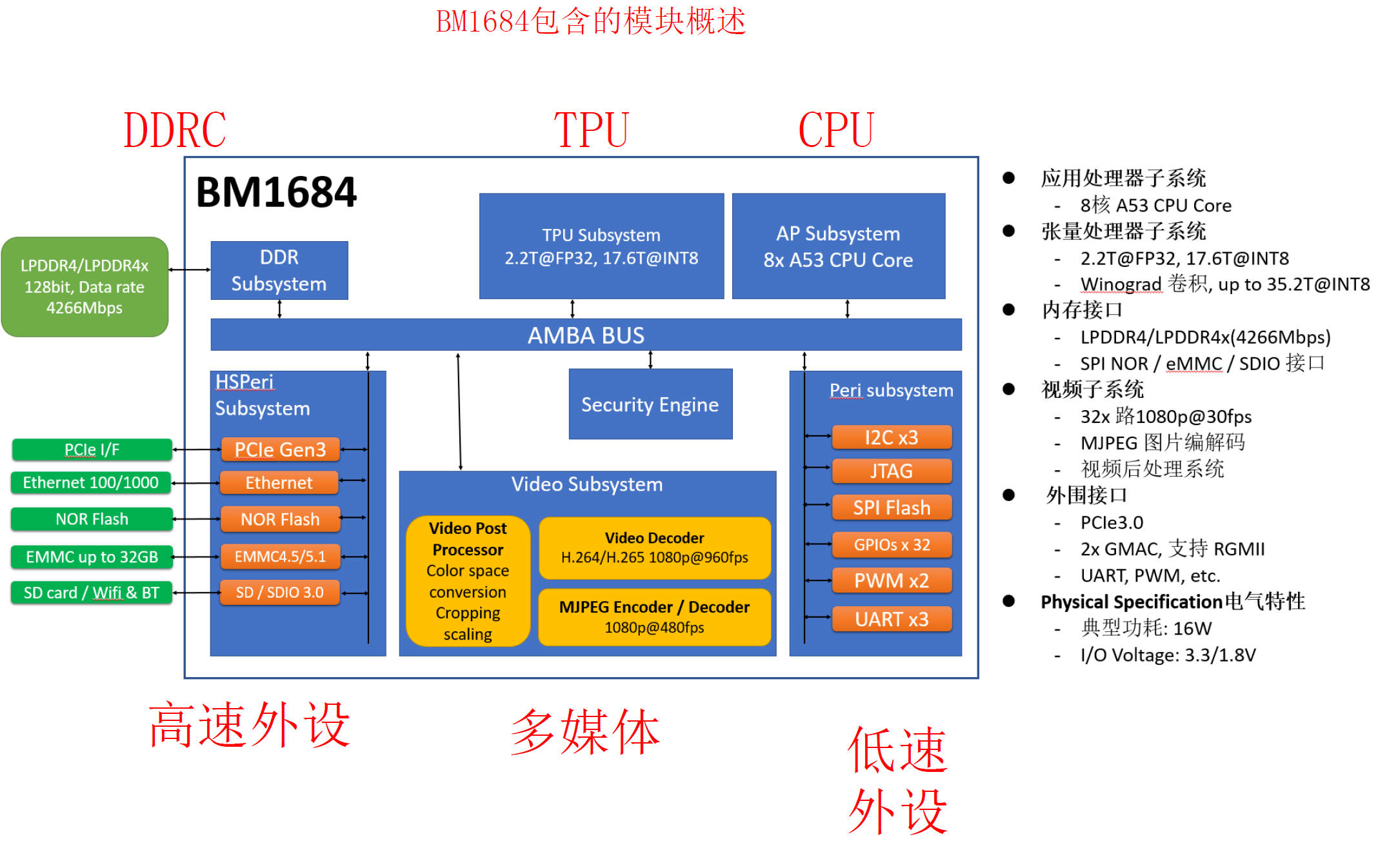
2.3.1. BM1684 TPU的基本架构?¶
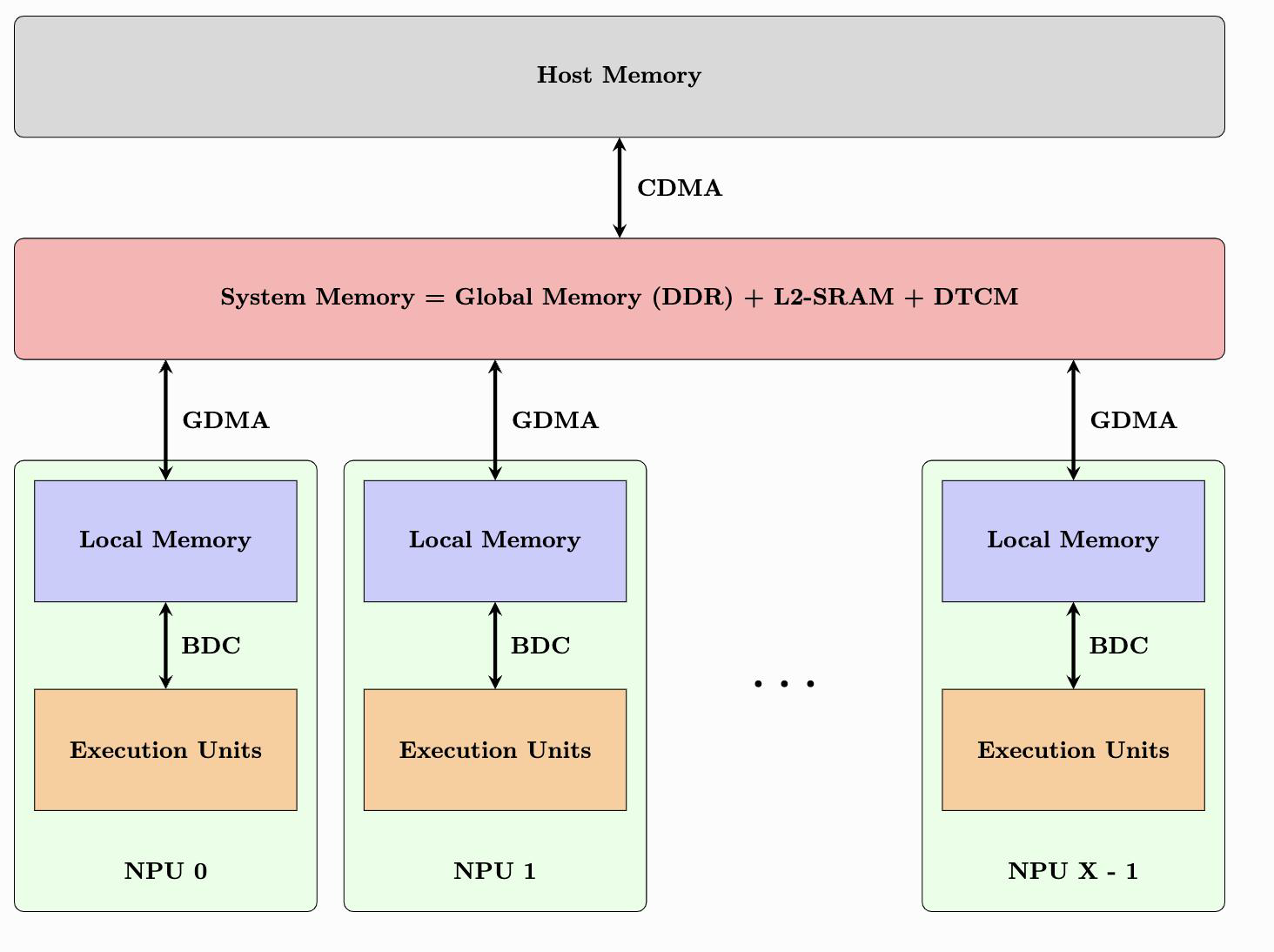
BM1684 TPU是SIMD(Single Instruction Mulit Data)单指令多数据流众核架构,内部主要包括BDC(SIMD 的控制器,控制EU做运算 )和GDMA(memory间的数据搬运)。1684 内部还有1个32位MCU ARM9,在运行动态编译生成的bmodel时将发送指令给TPU完成运算;EU运算单元1024个 = 16 个 * 64个NPU;Local Memory 32MB = 512KB * 64个NPU,用于存放EU原子操作的输入输出数据 。
2.3.2. 什么是DTCM?¶
答:DTCM是TPU内部的MCU ARM9的高速缓存空间(512KB)。
2.3.3. TPU的峰值算力是多少?¶
答:
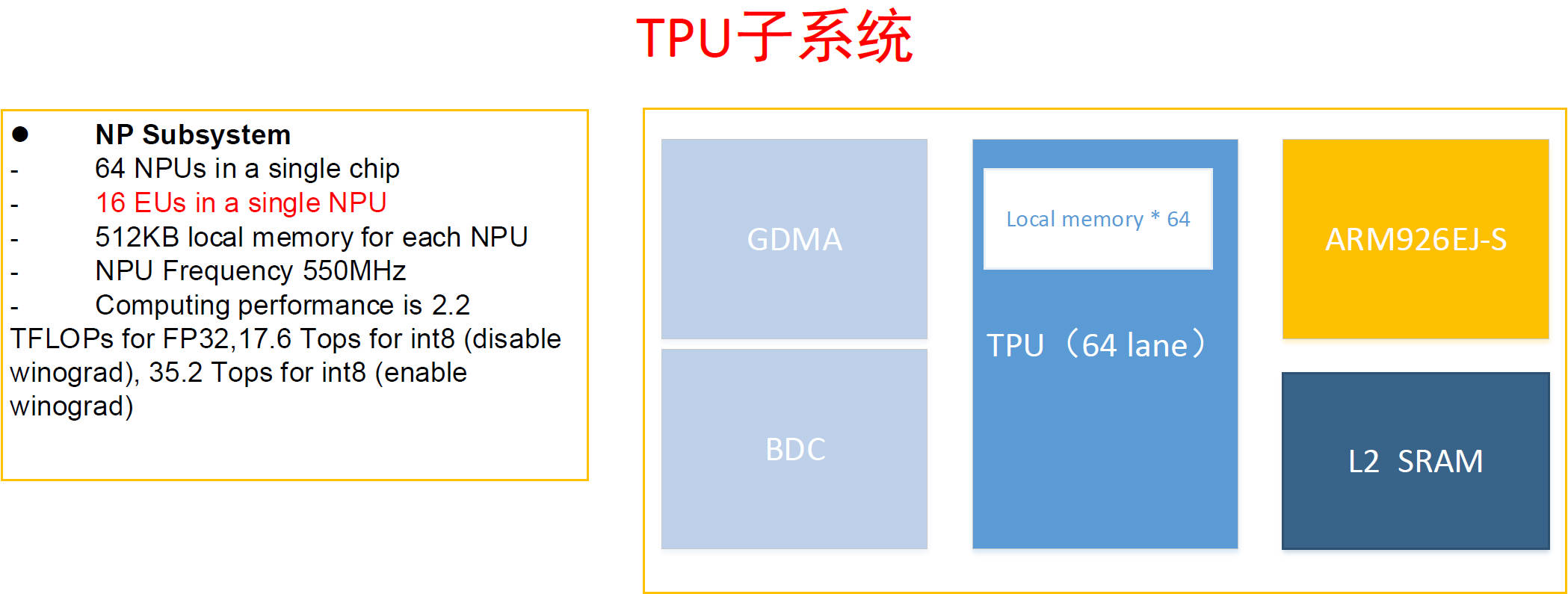
峰值算力:
FP32峰值算力 = 64 * 16 * 2(FP32 MAC) * 2 * 0 55G / 1024 = 2.2 TOPS
INT8峰值算力 = 64 * 16 * 16(INT8 MAC) * 2 * 0 55G / 1024 = 17.6 TOPS
如果enable winograd INT8的算力可以提高一倍,winograd 要求卷积核必须是3*3,会增大神经网络weight权值的体积 。
注解
这里乘以2的原因是每个周期可以做一个乘法加上一个加法,0.55是指工作频率是550MHz
2.4. 名词解释¶
术语 |
说明 |
|---|---|
BM1684 |
算能科技面向深度学习领域推出的第三代张量处理器 |
BM1684X |
算能科技面向深度学习领域推出的第四代张量处理器 |
VPU |
BM168x芯片中的解码单元 |
VPP |
BM168x芯片中的图形运算加速单元 |
JPU |
BM168x芯片中的图像jpeg编解码单元 |
SophonSDK |
算能科技基于BM168x芯片的原创深度学习开发工具包 |
PCIE Mode |
BM168x的一种工作形态,芯片作为加速设备来进行使用,客户算法运行于x86主机 |
SoC Mode |
BM168x的一种工作形态,芯片本身作为主机独立运行,客户算法可以直接运行其上 |
CModel |
BM168x软件模拟器,包含于SophonSDK中,在不具备 TPU 硬件设备的情况 下,可用于验证编译及完成模型转换 |
arm_pcie Mode |
BM168x的一种工作形态,搭载芯片的板卡作为PCIe从设备插到ARM cpu的服务器上,客户算法运行于ARM cpu的主机上 |
BMCompiler |
面向算能科技TPU 处理器研发的深度神经网络的优化编译器,可以将深度学习框架定义的各种深度神经网络转化为 TPU 上运行的指令流 |
BMRuntime |
TPU推理接口库 |
BMCV |
图形运算硬件加速接口库 |
BMLib |
在内核驱动之上封装的一层底层软件库,设备管理、内存管理、数据搬运、API发 送、A53使能、功耗控制 |
UFamework(ufw) |
算能自定义的基于Caffe的深度学习推理框架,用于将模型与原始框架解耦以便验证模型转换精度和完成量化 |
BMNetC |
面向Caffe的 BMCompiler 前端工具 |
BMNetD |
面向Darknet的BMCompiler前端工具 |
BMNetM |
面向MxNet的 BMCompiler 前端工具 |
BMNetO |
面向ONNX的BMCompiler前端工具 |
BMNetP |
面向PyTorch的 BMCompiler 前端工具 |
BMNetT |
面向TensorFlow的BMCompiler 前端工具 |
BMNetU |
INT8量化模型的BMCompiler前端工具 |
BMPaddle |
面向Paddle Paddle的BMCompiler前端工具 |
Umodel |
算能自定义的UFamework下的模型格式,为量化模型时使用的中间模型格式 |
BModel |
面向算能TPU处理器的深度神经网络模型文件格式,其中包含目标网络的权重(weight)、TPU指令流等 |
BMLang |
面向TPU的高级编程模型,用户开发时无需了解底层TPU硬件信息 |
OKKernel(BMKernel) |
基于TPU原子操作(根据芯片指令集封装的一套接口)的开发库,需熟悉芯片架构、存储细节 |
SAIL |
支持Python/C++接口的Sophon Inference推理库,是对BMCV、BMDecoder、 BMLib、BMRuntime等的进一步封装 |
winograd |
一种卷积的加速算法 |