本文档旨在让开发者快速了解TPU-KERNEL的开发流程和步骤,及相关的测试步骤;不涉及具体的代码说明、开发技巧及API使用参考,如需要详细了解,可参考doc目录下的《TPU-KERNEL开发参考手册.pdf》。
TPU-KERNEL概述
TPU-KERNEL为用户提供了一种直接在TPU设备编程的开发环境。开发者可以在设备(TPU)写自定义的算子,和TPU-KERNEL提供的firmware库进行链接,打包成TPU上可以运行的固件。下载到设备中后,在主机的应用中调用,实现利用TPU加速计算的目的。
TPU上面包含一个单核A53 ARM处理器(A53Lite),TPU实际的计算单元都通过该处理器进行配置与运行。所以固件的编译需要利用aarch64-none版本的交叉编译工具。
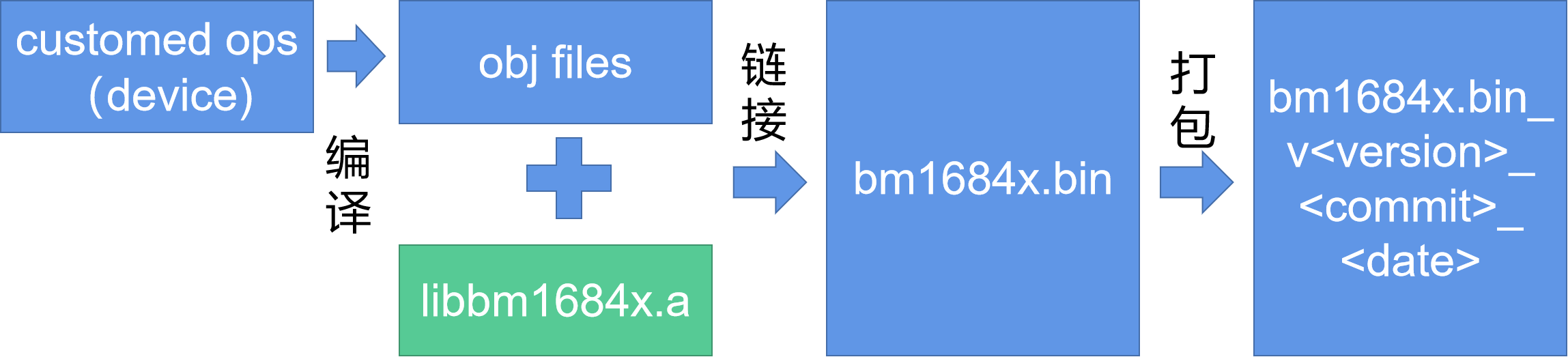
下面是编译固件的基本流程,开发者利用TPU-KERNEL调用设备的API,实现自己的算子。完成编写后,利用交叉编译工具,编译成obj文件,然后与TPU-KERNEL提供的底库libbm1684x.a进行链接,形成完整的固件程序。然后利用打包工具,在firmware写上设备id、版本号等信息,形成最终以bm1684x_v<VERSION>-<COMMIT>-<DATE>命名的文件。
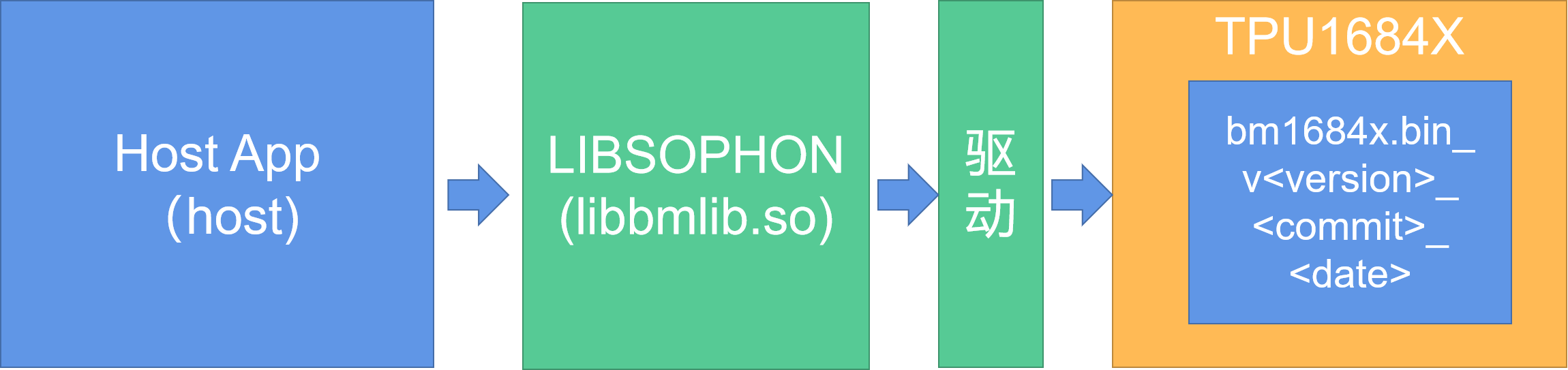
下面是使用的流程。首先,先利用提供的工具,将固件加载到TPU中。将在主机程序中调用LIBSOPHON(libbmlib.so)中的TPU-KERNEL通信函数,将算子参数及输入输出地址通过驱动发送到固件中,最终实现运行目的。
下面是TPU-KERNEL开发包的目录结构
├── README.md # 环境初始化说明文件
├── doc/
│ ├── TPU-KERNEL开发快速指南.pdf
│ └── TPU-KERNEL开发参考手册.pdf
├── scripts/
│ ├── envsetup.sh # 环境初始化脚本,设定交叉工具链及环境变量
│ ├── build_firmware.sh # 编译固件脚本
│ ├── firmware_pack.py # 固件打包脚本,会在build_firmware.sh中调用
│ ├── load_firmware.py # 加载固件脚本
│ └── firmware_info.py # 查看固件的内部信息
├── include/
│ ├── tpu_defs.h # 和TPU相关的通用定义,如类型、枚举、宏等
│ │ # 可以在device和host程序中使用
│ ├── tpu_fp16.h # fp16相关定义
│ ├── common.h # 一些通用定义, 如数据类型等
│ ├── device/tpu_kernel.h # tpu-kernel指令调用接口,只能在device代码中调用
│ └── ...
├── lib/
│ ├── libbm1684x.a # 供设备代码链接使用的底库
│ └── ...
├── samples/ # 一些示例用于演示工程结构与测试性能
│ ├── README.md # samples使用说明
│ ├── host/ # host上运行的代码
│ ├── device/ # device上运行的代码,自定义算子
│ ├── include/ # host和device的通信协议的数据结构
│ ├── CMakeList.sh # 构建脚本
│ └── ...
└── firmware/
└── bm1684x.bin_v<VERSION>-<COMMIT>-<DATA> # 原始固件
TPU-KERNEL环境初始化
依赖介绍
TPU-KERNEL开发需要用到如下交叉编译链,可以直接点击链接下载,或者用我们的的脚本自动初始化,下文会详细介绍
此外,TPU-KERNEL的host程序开发,需要依赖LIBSOPHON和驱动环境,可以从官网下载如下文件:
sophon-libsophon_*.deb
sophon-libsophon-dev_*.deb
sophon-driver_*.deb
初始化步骤
首先安装LIBSOPHON环境,如果已经安装过,可以略过这一步
# 将LIBSOPHON的相关软件包放到当前目录下
sudo dpkg -i sophon-driver*.deb
sudo dpkg -i sophon-libsophon*.deb
之后初始化编译环境
# 下载的tpu-kernel_v<VERSION>_<COMMIT>_<DATE>.tar.gz放到当前目录下
# 解压并进入解压出的目录
# 如果已经下载了上面的交叉编译工具,可以放到同一目录中,如/home/`whoami`/compilers
# 然后 export CROSS_TOOLCHAINS=/home/`whoami`/compilers
# 执行环境初始化脚本
source scripts/envsetup.sh
# 如果CROSS_TOOLCHAINS环境变量没有设置,
# 会设置CROSS_TOOLCHAINS=../toolchains_dir
# 如果CROSS_TOOLCHAINS设置的目录里没有所需要的交叉编译工具,
# 会自动从网上下载对应的交叉编译工具,并解压到该目录中
# 设置TPUKERNEL_TOP=`pwd`
PCIE模式
PCIE模式开发适用于在有PCIE板卡的机器上开发,相关程序包括上位机应用及固件编译好后,可以直接加载固件并运行。
环境初始化完成后,默认在此模式下。
# 命令行提示符最左边有 `(pcie)` 提示。
(pcie)my/current/work/path $
如果其他模式下,可以用 use_pcie 切换到此模式。
CMODEL模式
CMODEL模式开发适用于没有TPU设备,或者在机器上直接利用gdb来调试代码的情景。CMODEL是利用x86机器对TPU设备的模拟,运行比较慢,但能够直接利用gdb调试设备代码,也是开发过程中常用的模式。当在CMODEL下调试完成后,可以切换到PCIE或SOC模式下,到实际设备上运行程序。
可以用 use_cmodel 切换到此模式。
# 命令行提示符最左边有 `(cmodel)` 提示。
(cmodel)my/current/work/path $
SOC模式
SOC模式开发适用于SOC的TPU设备。基本工作流程是在x86的机器上交叉编译出应用和对应固件,然后复制到SOC设备上,先加载固件,再运行应用程序。
在此模式下,需要按照《LIBSOPHON使用手册》的 “ 使用libsophon开发 ” 一章中的 “ SOC MODE ” 进行环境初始化,并将soc_sdk的目录路径设置到SOC_SDK环境变量中,来指定soc的sdk位置
# /path_to_sdk/soc_sdk仅是示例,需要根据实际的设置进行修改
export SOC_SDK=/path_to_sdk/soc_sdk
可以用 use_soc 切换到此模式。
# 命令行提示符最左边有 `(soc)` 提示。
(soc)my/current/work/path $
Samples使用说明
TPU-KERNEL中的samples提供了一系列的算子开发和使用的示例,同时也提供了批量测试脚本,可以测试TPU在不同参数下的性能情况
下面示例仅以PCIE模式为主要说明,其他方式差异会进行备注
工程布局与编译
当前工程布局是实际算子开发时推荐的开发方式,里面包含了自动构建脚本,能够将firmware打包加载,并能够编译host程序。主要目录或文件说明如下:
├── CMakeLists.txt # host程序和固件自动构建脚本
├── device/ # 设备上运行的自定义算子,会和libbm1684x.a一起生成固件
├── host/ # 主机上的应用程序
├── include/ # 包含主机和设备均可使用或共用的数据类型或结构定义
└── test/ # 批量测试脚本
PCIE模式编译
cd samples
# 当前已处于tpu-kernel/samples目录下
mkdir build && cd build
# 编译Release版本的主机程序
cmake ../
# 如果要编译Debug版本的主机程序, 可以执行
# cmake ../ -DCMAKE_BUILD_TYPE=Debug
# 编译device目录中的自定义算子,并与libbm1684x.a进行链接
# 最终生成firmware/bm1684x.bin_v<VERSION>-<COMMIT>-<DATE>
make firmware
# 由于host程序用的是device_id=0的BM1684X设备,
# 所以只能加载编译出的固件到device_id=0且为BM1684X的设备上
make load
# 加载成功后,可以用dmesg命令,会有以下字样的输出
# ...
# [ 14.505087] bmdrv: bmsophon0 firmware init done!, status = 0x6125438
# [ 14.505168] bmdrv: firmware load success!
# ...
# 编译主机的应用程序
make -j
CMODEL模式编译
cd samples
# 当前已处于tpu-kernel/samples目录下
mkdir build_cmodel && cd build_cmodel
# 为方便调试,默认编译的是Debug版本程序
cmake ../
# 编译device目录中的自定义算子,并与libbm1684x_cmodel.so进行链接
# 最终在当前目录生成 libfirmware_cmodel.so
make firmware
# 指定生成的cmodel版的firmware,
# set_cmodel_firmware是envsetup.sh提供的命令
set_cmodel_firmware libfirmware_cmodel.so
# 编译主机的应用程序
make -j
SOC模式编译
cd samples
# 当前已处于tpu-kernel/samples目录下
mkdir build_soc && cd build_soc
# 默认编译的是Release版本程序
cmake ../
# 编译device目录中的自定义算子,并与libbm1684x.a进行链接
# 最终生成firmware/bm1684x.bin_v<VERSION>-<COMMIT>-<DATE>
make firmware
# 编译主机的应用程序
make -j
# 收集soc上用到的相关文件
# 会在当前目录下生成install文件夹
make install
运行方法与pcie及cmodel有所差异,运行方法如下
将当前目录生成的install文件夹全部复制到SOC设备上
# 假设:
# 1. 已经登录到soc设备上,复制了install完整文件夹
# 2. 有完整的且版本和编译所用的SDK匹配libsophon环境
# 3. 当前目录为install目录
# 加载固件
python3 scripts/load_firmware.py --firmware firmware/bm1684x.bin*
cd bin
# 运行测试程序,这里以tpu_crop为例
# 单次运行
./tpu_crop
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
python3 ../test/batch_test_crop.py
算子功能说明
经过上一步的编译,会在当前build目录下生成以下应用,分别对应以下将要说明的算子,同时在../test中会有相关的batch_test_xxx.py的批量测试脚本,用于性能测试
tpu_gemm
tpu_database_topk
tpu_database_group_topk
tpu_multi_crop_resize
tpu_rgb2yuv
tpu_yuv2rgb_formula
tpu_yuv2rgb_lookup_table
tpu_warp_affine
tpu_warp_affine_bilinear
tpu_crop
tpu_rpn
tpu_hanming_distance
tpu_image_resize
tpu_pad
tpu_crop_and_resize
tpu_resize_using_lut
test_yuv_deinterleave
注意: 以上程序只能运行在device_id=0的BM1684X的设备上
GEMM
GEMM(General Matrix Multiplication)通用矩阵乘法是TPU的典型运算,本示例会计算shape为MxK和KxN的两个矩阵乘法。
相关文件包括
include/tpu_api_protocol.h
host/tpu_gemm.cpp
device/tpu_device_gemm.c
test/batch_test_gemm.py
下面是`tpu_gemm`命令的相关使用说明:
# 打印使用说明
./tpu_gemm -h
# 输出如下
# --L_ROW(-m) xxx : Left matrix row, default 10
# --L_COL(-k) xxx : Left matrix columns, default 10
# --R_COL(-n) xxx : Right matrix columns, default 20
# --idtype(-i) xxx : input data_type, 5:FP32, 3:FP16, 1:INT8, 0:UINT8, 7:INT16, 6:UINT16, 9:INT32, 8:UINT32, 11:BFP16 default: FP32
# --odtype(-o) xxx : output data_type, default: FP32
# --seed(-s) xxx : set test seed
# --compare(-c) xxx : need compare result, default=1
# 默认参数运行
./tpu_gemm
# 输出如下
# L_row=10, L_col=10, R_col=20, L=F32, R=F32, Y=F32, time=13(us) --> success
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 如果测试时开启比对,由于还要做本地矩阵计算,运行时间很长
# 最终会生成GEMM.csv文件
# 以下针对pcie平台测试
# 关闭比对测试
python3 ../test/batch_test_gemm.py 0
# 开启比对测试(不建议在CMODEL、SOC下或仅关心性能情况下运行)
python3 ../test/batch_test_gemm.py 1
# 以下针对SOC平台下测试
# 由于SOC上资源受限,仅测试所需设备内存在2G以下的cases,并关闭比对
MAX_MEM=2*1024*1024*1024 python3 ../test/batch_test_gemm.py 0
全库TopK
全库TopK是基于行人数据库场景模拟的操作,数据结构与参数如下:
假设每条行人数据有所在库ID、性别、是否戴帽、置信度四个属性
一共有db_num个数据库
所有total_people_num数据根据所在库ID随机分布在这db_num个数据库中
算子运行流程如下:
从db_num个数据库中选出db_sel_num个数据库的数据,并根据性别、是否戴帽、置信度设定数据过滤选项, 利用TPU执行数据过滤
此时过滤出的数据混在一起, 将这些数据按照置信度属性选择前K个最大值和对应的原始index
Related files:
include/tpu_api_protocol.h
host/tpu_database_topk.cpp
device/tpu_device_attr_filter.c
device/tpu_device_topk.c
test/batch_test_topk.py
tpu_database_top 使用:
# 参数含义见上面数据结构与参数说明部分
./tpu_database_topk [total_people_num] [db_num] [db_sel_num] [k]
# Default settings:
# total number of people is 1000000,
# total number of databases is 64,
# select 64 databases,
# get the top 10 item
./tpu_database_topk
# Custom settings:
# total number of people is 1000000,
# total number of databases is 64,
# select 5 databases,
# get the top 1 item
./tpu_database_topk 1000000 64 5 1
# 输出如下
# TopK total_people_num=1000000, db_num=64, db_sel_num=5, k=1, avg_time=0.8205(ms)
# --> Topk value: [ 99.9954 ]
# --> Topk index: [ 999954 ]
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终会输出topk.csv
python3 ../test/batch_test_topk.py
分库TopK
分库TopK是基于行人数据库场景模拟的操作,数据结构与参数如下:
假设每条行人数据有所在库ID、性别、是否戴帽、置信度四个属性
一共有db_num个数据库
所有total_people_num数据根据所在库ID随机分布在这db_num个数据库中
算子运行流程如下:
从db_num个数据库中选出db_sel_num个数据库的数据,并根据性别、是否戴帽、置信度设定数据过滤选项,利用TPU执行数据过滤
利用TPU将混在一起的数据按照所在库ID将分成db_sel_num组
分别将每组中数据按照置信度选择前K个最大值,最终会输出db_sel_num组value和index结果
和全库TopK区别在于全库TopK是把过滤出的数据放到一起,选其中的前K条数据,而分库是把过滤出的数据按照数据库ID分开,分别在db_sel_num个数据库中取前K条数据
相关文件如下:
include/tpu_api_protocol.h
host/tpu_database_group_topk.cpp
device/tpu_device_attr_filter.c
device/tpu_device_db_seperate.c
device/tpu_device_topk.c
test/batch_test_group_topk.py
tpu_database_group_topk 使用说明:
# 参数含义见上面数据结构与参数说明部分
./tpu_database_group_topk [total_people_num] [db_num] [db_sel_num] [k]
# Default settings:
# total number of people is 1000000,
# total number of databases is 64,
# select 64 databases,
# get the top 10 item
./tpu_database_group_topk
# Custom settings:
# total number of people is 1000000,
# total number of databases is 64,
# select 5 databases,
# get the top 1 item
./tpu_database_group_topk 1000000 64 5 1
# output as follows:
# Group TopK total_people_num=1000000, db_num=64, db_sel_num=5, k=1, avg_time=1.2234(ms)
# --> Group 0 Topk value: [ 99.9778 ]
# --> Group 0 Topk index: [ 999778 ]
# --> Group 1 Topk value: [ 99.9634 ]
# --> Group 1 Topk index: [ 999634 ]
# --> Group 2 Topk value: [ 99.989 ]
# --> Group 2 Topk index: [ 999890 ]
# --> Group 3 Topk value: [ 99.9954 ]
# --> Group 3 Topk index: [ 999954 ]
# --> Group 4 Topk value: [ 99.9942 ]
# --> Group 4 Topk index: [ 999942 ]
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终会输出group_topk.csv
python3 ../test/batch_test_group_topk.py
Multi_Crop_Resize
tpu_multi_crop_resize 展示了如何对一张图像按照roi_num(1到10之间)个框进行crop,并将crop出来的roi图像resize成给定的输出大小
相关文件如下:
include/tpu_api_protocol.h
host/tpu_multi_crop_resize.cpp
device/tpu_device_multi_crop_resize.c
test/batch_test_multi_crop_resize.py
tpu_multi_crop_resize 使用说明:
./tpu_multi_crop_resize roi_num src_format dst_format src_h src_w roi_h roi_w dst_h dst_w
# roi_num: the number of cropped images
# src format: the format of the input image, 0-YUV420P, 3-NV12, 8-RGB_PLANAR, 14-GRAY
# dst_format: the format of the output image, 0-YUV420P, 3-NV12, 8-RGB_PLANAR, 14-GRAY
# src_h: the height of the input image
# src_w: the width of the input image
# roi_h: the height of the cropped image
# roi_w: the width of the cropped image
# dst_h: the height of the output image
# dst_w: the width of the output image
# 使用示例
# ./tpu_multi_crop_resize 5 0 3 1280 720 1280 720 960 540
# [TPUKERNEL-MULTI_CROP_RESIZE] src_format: 0 dst_format: 3 roi_num: 5 src_h: 1280 src_w: 720 roi_h: 1280 roi_w: 720 dst_h: 960 dst_w: 540
# using time= 67165(us)
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终会生成multi_crop_and_resize.csv
python3 ../test/batch_test_multi_crop_resize.py
RGB to YUV
RGB to YUV 实现了RGB图像到YUV格式的转换,目前输出的YUV只支持I420。
相关文件包括:
include/tpu_api_protocol.h
host/tpu_rgb2yuv.cpp
device/tpu_device_cv_rgb2yuv.c
test/batch_test_rgb2yuv.py
tpu_rgb2yuv 使用说明
./tpu_rgb2yuv [input_height] [input_width]
# input image resolution: 32 * 32 | 64 * 64 | 96 * 96 |
128 * 128 | 256 * 256 | 384 * 384 |
512 * 512 | 960 * 540 | 1280 * 720
# output image resolution: Same size as input image.
# 使用示例
./tpu_rgb2yuv 256 256
# 输出如下
# ---------------parameter-------------
# width=256, height=256
#
# - rgb2yuv TPU using time= 86(us)
# rgb2yuv successful!
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终会输出rgb2yuv.csv文件
python3 ../test/batch_test_rgb2yuv.py
YUV to RGB Based on formula method
YUVtoRGB 实现了YUV格式图像转换为BGR Planner格式,目前只支持I420、NV12、NV21。
相关文件包括:
include/tpu_api_protocol.h
host/tpu_yuv2rgb_formula.cpp
device/tpu_device_cv_yuv2rgb_formula.c
test/batch_test_yuv2rgb_formula
tpu_yuv2rgb_formula 使用说明
./tpu_yuv2rgb_formula [src_image_format] [output_data_format] [output_height] [output_width]
# output image resolution: 32 * 32 | 64 * 64 | 96 * 96 |
# 128 * 128 | 256 * 256 | 384 * 384 |
# 512 * 512 | 640 * 640 | 1280 * 720
# src_image_format : I420 (0) | NV12 (3) | NV21 (4)
# output_data_format : FP32 (0) | U8 (1) | FP16 (5)
# 使用示例
./tpu_yuv2rgb_formula 0 0 128 128
---------------parameter-------------
input_height: 128
input_width: 128
src_image_format: YUV420
output_data_format: FP32
-------------------------------------
----- using time: 101us -----
------[TEST YUV2RGB] ALL TEST PASSED!
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终会输出yuv2rgb_formula.csv文件
python3 ../test/batch_test_yuv2rgb_formula.py
YUV to RGB Based on the look-up table method
YUVtoRGB 实现了YUV格式图像转换为BGR Planner格式,目前只支持I420、NV12、NV21。
相关文件包括:
include/tpu_api_protocol.h
host/tpu_yuv2rgb_lookup_table.cpp
device/tpu_device_cv_yuv2rgb_lookup_table.c
test/batch_test_yuv2rgb_lookup_table
tpu_yuv2rgb_lookup_table 使用说明
./tpu_yuv2rgb_lookup_table [src_image_format] [output_data_format] [output_height] [output_width]
# output image resolution: 32 * 32 | 64 * 64 | 96 * 96 |
# 128 * 128 | 256 * 256 | 384 * 384 |
# 512 * 512 | 640 * 640 | 1280 * 720
# src_image_format : I420 (0) | NV12 (3) | NV21 (4)
# output_data_format : FP32 (0) | U8 (1) | FP16 (5)
# 使用示例
./tpu_yuv2rgb_lookup_table 0 0 128 128
---------------parameter-------------
input_height: 128
input_width: 128
src_image_format: YUV420
output_data_format: FP32
-------------------------------------
----- using time: 97us -----
------[TEST YUV2RGB] ALL TEST PASSED!
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终会输出yuv2rgb_lookup_table.csv文件
python3 ../test/batch_test_yuv2rgb_lookup_table.py
Warp Affine
Warp affine实现了图像的仿射变换,可以实现对图像的平移、缩放、旋转操作,目前该接口支持RGB Planer格式。
相关文件包括:
include/tpu_api_protocol.h
host/tpu_warp_affine.cpp
device/tpu_device_warp_affine.c
test/batch_test_warp_affine.py
tpu_warp_affine 使用说明:
./tpu_warp_affine [input_height] [input_width] [output_height] [output_width]
# input image resolution: 68 * 68 | 128 * 128 | 384 * 336 | 410 * 720
# output image resolution: 64 * 64 | 112 * 112 | 224 * 224 | 384 * 384 | 400 * 400
./tpu_warp_affine 128 128 64 64
# 输出如下:
# ---------------parameter-------------
# input_height: 128
# input_width: 128
# output_height: 64
# output_width: 64
# -------------------------------------
# -- warp_affine TPU using time: 207us --
# ------[WARP_AFFINE TEST PASSED!]------
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终会输出warp_affine.csv文件
python3 ../test/batch_test_warp_affine.py
Warp Affine Bilinear
Warp affine bilinear实现了图像的仿射变换,可以实现对图像的平移、缩放、旋转操作,目前该接口支持RGB Planer和Gray格式。
相关文件包括:
include/tpu_api_protocol.h
host/tpu_warp_affine_bilinear.cpp
device/tpu_device_warp_affine_bilinear.c
test/batch_test_warp_affine_bilinear.py
tpu_warp_affine_bilinear Instructions for use:
./tpu_warp_affine_bilinear [flag] [input_data_format] [output_data_format] [image_format] [input_height] [input_width] [output_height] [output_width]
# flag: 0 表示测试特定的参数;1 表示测试 1024 以内的随机宽高图像;2 表示测试1024到2048之间随机宽高的图像;3 表示测试2048到4096之间随机宽高的图像
# input_data_format: 0 --> fp32 ; 1 --> u8
# output_data_format: 0 --> fp32 ; 1 --> u8
# image_format: 9 --> bgr ; 14 --> gray
# input image resolution: larger than the width and height of the output image
# output image resolution: 2 * 2 -----> 4096 *4096
./tpu_warp_affine_bilinear 0 0 0 9 2000 2000 128 128
# 输出如下:
# ---------------parameter-------------
# input_height: 2000
# input_width: 2000
# image_height: 128
# image_width: 128
# image_format: FORMAT_MAPPING_BGR_PLANAR
# input_data_format: FP32
# output_data_format: FP32
# -------------------------------------
# -- warp affine bilinear TPU using time: 7282(us) --
# ------[WARP_AFFINE BILINEAR TEST PASSED!]------
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终输出 warp_affine_bilinear.csv文件
python3 ../test/batch_test_warp_affine_bilinear.py
Crop
Crop实现了将输入图像按照指定大小进行裁剪,目前支持YUV420P、NV12、NV21三种格式
相关的文件包括:
include/tpu_api_protocol.h
host/tpu_crop.cpp
device/tpu_device_crop.c
test/batch_test_crop.py
tpu_crop 使用说明:
./tpu_crop format input_h input_w output_h output_w
# format: the format of the input and output images, 0-YUV420P, 3-NV12, 4-NV21
# input size: the input image size, input_h * input_w
# output size: the output image size, output_h * output_w
# 输出如下:
# ./tpu_crop 4 1280 720 32 32
# format: 4
# input size: 1280 * 720
# output size: 32 * 32
# using time= 69(us)
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终输出crop.csv文件
python3 ../test/batch_test_crop.py
Yuv Deinterlace
Yuv deinterlace实现了NV12/NV21格式到I420格式的转换
相关的文件包括:
include/tpu_api_protocol.h
host/tpu_yuv_deinterlace.cpp
device/tpu_device_yuv_deinterlace.c
test/batch_test_yuv_deinterlace.py
tpu_yuv_deinterlace 使用说明:
./tpu_yuv_deinterlace img_h img_w src_format
# img_size: the size of image, img_h * img_w
# format: the format of the input images, 3-NV12, 4-NV21
# 输出如下:
# ./tpu_yuv_deinterlace 1920 1080 3
# img_size : 1920 * 1080
# format: 3
# using time: 486us
# 批量测试(不建议在cmodel模式下运行, 时间会比较长)
# 最终输出yuv_deinterlace.csv文件
python3 ../test/batch_test_yuv_deinterlace.py
Hanming distance
汉明距离表示两个相同长度的字符串在相同位置上不同字符的个数.
相关的文件包括:
include/tpu_api_protocol.h
host/tpu_hanming_distance.cpp
device/tpu_device_hm_distance.c
test/batch_test_hm_distance.py
tpu_hanming_distance 使用说明:
./tpu_hanming_distance vec_dims query_num database_num # vec_dims: 8 # query_num : <= 32 # database_num : <= 20000000 # 输出如下: # ./tpu_hanming_distance 8 32 100000 # using time: 33701 us # 批量测试,最终输出 tpu_hanming_distance.csv文件 python3 ../test/batch_test_hanming_distance.py
RPN
RPN(Region Proposal Networks)是Faster RCNN出新提出来的proposal生成网络。
相关文件包括
include/tpu_api_protocol.h
host/tpu_rpn.cpp
device/tpu_device_rpn.c
test/batch_test_rpn.py
下面是`tpu_rpn`命令的相关使用说明:
# 使用说明
./tpu_rpn batch_num feature_height feature_width compare
# batch_num : batch num, 默认为1
# feature_height : feature map's height, 默认14
# feature_width : feature map's wdith, 默认14
# compare : 是否执行cpu算法,并与cpu算法的结果进行比较, 1:比较 0:不比较
# 输出如下
# ./tpu_rpn 4 20 14 1
# batch_num: 4
# feat_stride: 16
# min_size: 16
# base_size: 16
# pre_nms_topN: 614
# post_nms_topN: 251
# nms_thresh: 0.41
# score_thresh: 0.81
# scales_num: 3
# ratios_num: 3
# map_height: 20
# map_width: 14
# score_out_flag: 0
# origin_w: 224
# origin_h: 320
# compare: 1
# Native detected box number: 130
# time=xx(us)
# result compare success
# 批量测试(不建议在cmodel模式下运行)
# 最终会生成rpn.csv文件
python3 ../test/batch_test_rpn.py
Resize
Resize实现将输入图像缩放至指定宽高
相关文件包括:
include/tpu_api_protocol.h
host/tpu_image_resize.cpp
device/tpu_device_image_resize.c
test/batch_test_image_resize.py
tpu_image_resize 使用说明:
./tpu_image_resize format src_h src_w dst_h dst_w if_padding padding_r padding_g padding_b
# format: the format of src_image and dst_image, 0-YUV420P 3-NV12 4-NV21 9-BGR_PLANAR 14-GRAY
# src_image_size: the size of src image, src_h * src_w
# dst_image_size: the size of dst_image, dst_h * dst_w
# if_padding: 0-Scale proportionally and fill according to the set pixel value
# 1-Non-proportional scaling
# padding_r: the filled value of r channel
# padding_g: the filled value of g channel
# padding_b: the filled value of b channel
# 输出如下:
# ./tpu_image_resize 0 1024 2048 200 200 0 1 2 3
# src_format: 0
# dst_format: 0
# src_h: 1024
# src_w: 2048
# dst_h: 200
# dst_w: 200
# if_padding: 0
# time=xx(us)
# 批量测试(不建议在cmodel模式下运行)
# 最终会生成image_resize.csv文件
python3 ../test/batch_test_image_resize.py
Crop And Resize
Crop And Resize 实现对一张图像按照roi_num(1到10之间)个框进行crop,并将crop出来的roi图像缩放成给定的输出大小
相关文件包括:
include/tpu_api_protocol.h
host/tpu_crop_and_resize.cpp
device/tpu_device_crop_and_resize.c
test/batch_test_crop_and_resize.py
tpu_crop_and_resize 使用说明:
./tpu_crop_and_resize roi_num format src_h src_w roi_h roi_w dst_h dst_w padding_r padding_g padding_b
# roi_num: the num of cropped image
# format: the format of src_image and dst_image, 0-YUV420P 3-NV12 4-NV21 9-BGR_PLANAR 14-GRAY
# src_image_size: the size of src image, src_h * src_w
# roi_image_size: the size of cropped images, roi_h * roi_w
# dst_image_size: the size of dst_image, dst_h * dst_w
# padding_r: the filled value of r channel
# padding_g: the filled value of g channel
# padding_b: the filled value of b channel
# 输出如下:
# ./tpu_crop_and_resize 2 3 2048 1920 200 100 600 600 1 2 3
# roi_num: 2
# src_format: 3
# dst_format: 3
# src_h: 2048
# src_w: 1920
# roi_h: 200
# roi_w: 100
# dst_h: 600
# dst_w: 600
# time=xx(us)
# 批量测试(不建议在cmodel模式下运行)
# 最终会生成crop_and_resize.csv文件
python3 ../test/batch_test_crop_and_resize.py
Test Instructions
Test Instructions 通过运算指定的TPU指令,以测试TPU的算力,建议在pcie模式或soc模式下运行。
相关文件包括:
include/tpu_api_protocol.h
host/tpu_test_instrutions.cpp
device/tpu_test_instrutions.c
test/batch_test_instructions.py
tpu_test_instrutions 使用说明:
./tpu_test_instrutions [instrution_type] [data_type]
# instrution_type: the type of instrution, INS_CONV | INS_MAT_MUL2
# data_type: the type of input data, INS_CONV supports DT_INT8, DT_FP16 and DT_FP32, INS_MAT_MUL2 supports DT_INT8 and DT_FP16.
# 输出如下:
# ./tpu_test_instrutions INS_MAT_MUL2 DT_INT8
# ================= start test MAT MUL 2 =================
# data type: DT_INT8 loop times: 1000
# --case 0
# mm2 param: left matrix=(1024 2048), right matrix=(2048 1024)
# TPU total time= 131580(us) TPU avg time= 131.58(us) TPU computing power= 32.64T
# --case 1
# mm2 param: left matrix=(1024 2048), right matrix=(2048 1024) l_matrix is transposed. r_matrix is transposed.
# TPU total time= 264195(us) TPU avg time= 264.20(us) TPU computing power= 32.51T
# --case 2
# mm2 param: left matrix=(1024 2048), right matrix=(1024 2048) r_matrix is transposed.
# TPU total time= 135638(us) TPU avg time= 135.64(us) TPU computing power= 31.66T
# 批量测试(不建议在cmodel模式下运行)
# 最终会生成tpu_test_instrutions.csv文件
# 会依次在命令行中执行所有支持的命令类型
python3 ../test/batch_test_instructions.py
附录1: 批量测试通用使用方法
在samples/test目录下会有命名如batch_test_xxx.py的测试脚本,可以通过环境变量 CASE_START, CASE_COUNT 来控制测试case的起始和运行个数。当脚本运行完成后,会生成xxx.csv文件,里面会记录CASE参数与运行时间。 下面以 batch_test_topk.py 为例进行说明:
假设当前在sample/build目录下,并且已经编译好应用程序。
# 运行CASE {5, 6}. 注意索引从0开始
CASE_START=5 CASE_COUNT=2 python3 ../test/batch_test_topk.py
# 运行所有CASES
python3 ../test/batch_test_topk.py
```
batch_test.py是所有测试脚本的基础库, 里面的general_batch_test用法如下,在测试时可以自行写对应脚本
def general_batch_test(
command_params, exclude_func=None,
is_format=False, param_names=None, title=None):
"""
for 'command1 p0 p1 p2 p3 p4' test, let
is_format=False
command_params = [
("command1", [[p0_1, p0_2, p0_3], [(p1_0, p2_0), (p1_1, p2_1)], [(p3, p4)]]),
("command1", [[p0_4], [(p1_3, p2_3), (p1_4, p2_4)], [(p3, p4)]]),
]
will generate following cases:
command1 p0_1 p1_0 p2_0 p3 p4
command1 p0_1 p1_1 p2_1 p3 p4
command1 p0_2 p1_0 p2_0 p3 p4
command1 p0_2 p1_1 p2_1 p3 p4
command1 p0_3 p1_0 p2_0 p3 p4
command1 p0_3 p1_1 p2_1 p3 p4
command1 p0_4 p1_3 p2_3 p3 p4
command1 p0_4 p1_4 p2_4 p3 p4
for "command2 -m {} -n {] -k {}" test, let
is_format=True
command_params = [
("command2", [[p0_1, p0_2, p0_3], [(p1_0, p2_0), (p1_1, p2_1)]]),
]
will generate following cases:
command2 -m p0_1 -n p1_0 -k p2_0
command2 -m p0_1 -n p1_1 -k p2_1
command2 -m p0_2 -n p1_0 -k p2_0
command2 -m p0_2 -n p1_1 -k p2_1
command2 -m p0_3 -n p1_0 -k p2_0
command2 -m p0_3 -n p1_1 -k p2_1
exclude_func: func(param) filter invalid param combinations, the param is ignored when return True
param_names: use for generated csv file as csv table titles, such as ['m', 'k', 'n'] for 'command2' or ['p0', 'p1', 'p2', 'p3', '4' ] for 'command1'
title: generate {title}.csv file if not None
At last, the function will search time = *(*) or time: *(*) pattern in command outputs to collect time info, write into {title}.csv file
"""