TPU架构图
下面是BM1684x芯片的TPU架构图.
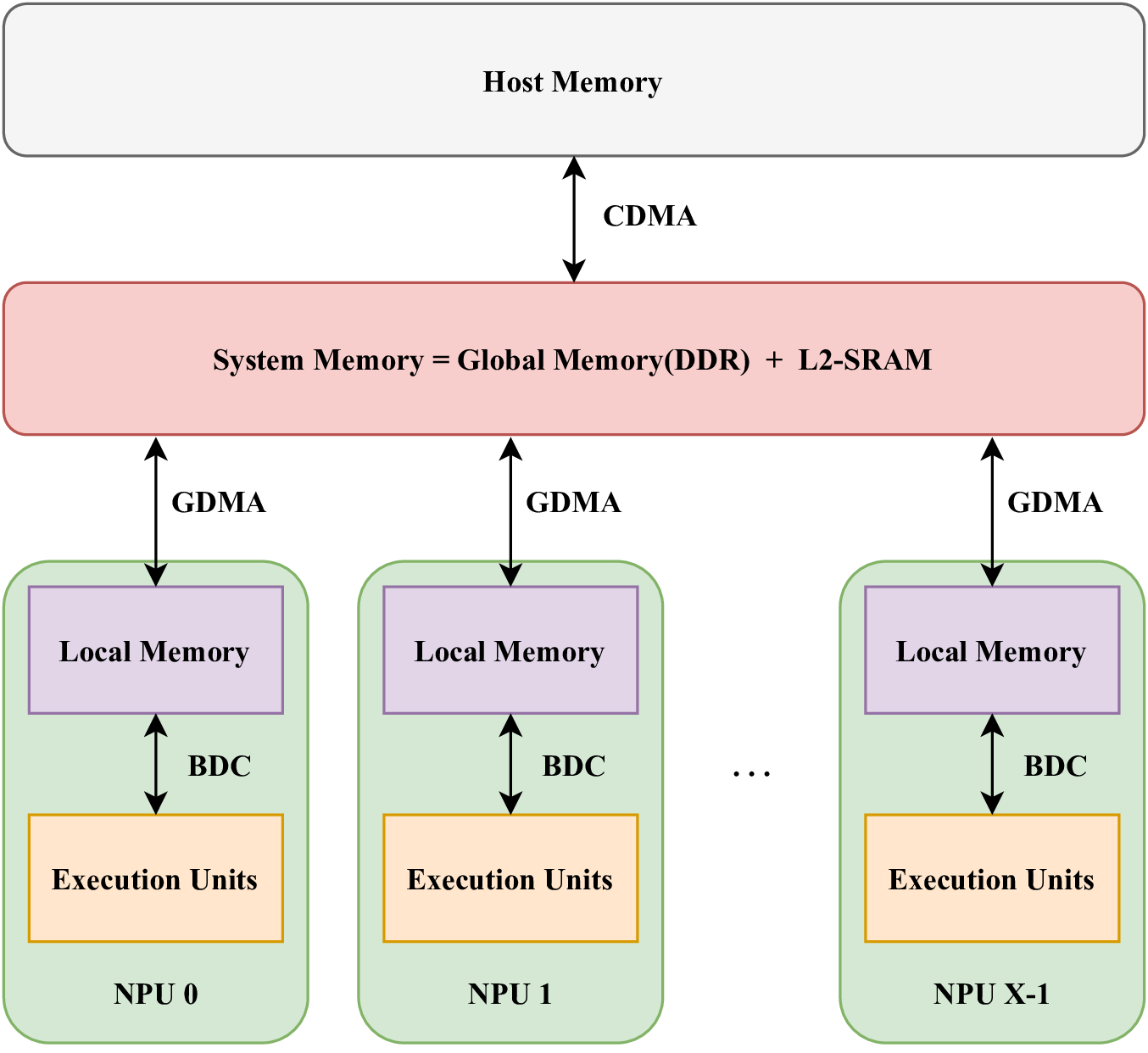
如上图所示,TPU是一种多个计算核的架构设计,每一个核被称之为 NPU(Neural network Processing Unit)。
TPU按照单指令多数据(Single Instruction Multiple Data,SIMD)的模式进行计算, 即在某一时刻所有的NPU都会执行同样的计算指令,但是每一个NPU操作的数据不一样。
在每一个NPU内部存储数据的内存被称之为Local Memory, 每个NPU的计算单元只能访问Local Memory。
TPU进行计算加速通常分为以下几步:
将数据从主机端内存搬运到TPU的系统内存(Global Memory)当中,
再将数据从系统内存(Global memory)再搬运到Local Memory当中,
驱动计算单元对Local Memory当中的数据进行计算,并将计算结果返回Local Memory,
将计算结果从Local Memory搬运回Global Memory,
将Global Memory中的计算结果搬运回主机端内存。
TPU的内存类型
在上面的介绍中,该TPU架构下,数据主要存在于以下的内存中:
- 系统内存(System Memory)
Global Memory: TPU芯片外的内存,DDR。
L2-SRAM: 片上内存,作为缓存。
Local Memory : 片上内存,BDC计算单元直接访问的内存类型。