4. 整体设计
4.1. 分层
TPU-MLIR将网络模型的编译过程分两层处理:
- Top Dialect
与芯片无关层, 包括图优化、量化、推理等等
- Tpu Dialect
与芯片相关层, 包括权重重排、算子切分、地址分配、推理等等
整体的流程如(TPU-MLIR整体流程)图中所示, 通过Pass将模型逐渐转换成最终的指令, 这里具体说明Top层和Tpu层每个Pass做的什么功能。 后面章节会对每个Pass的关键点做详细说明。
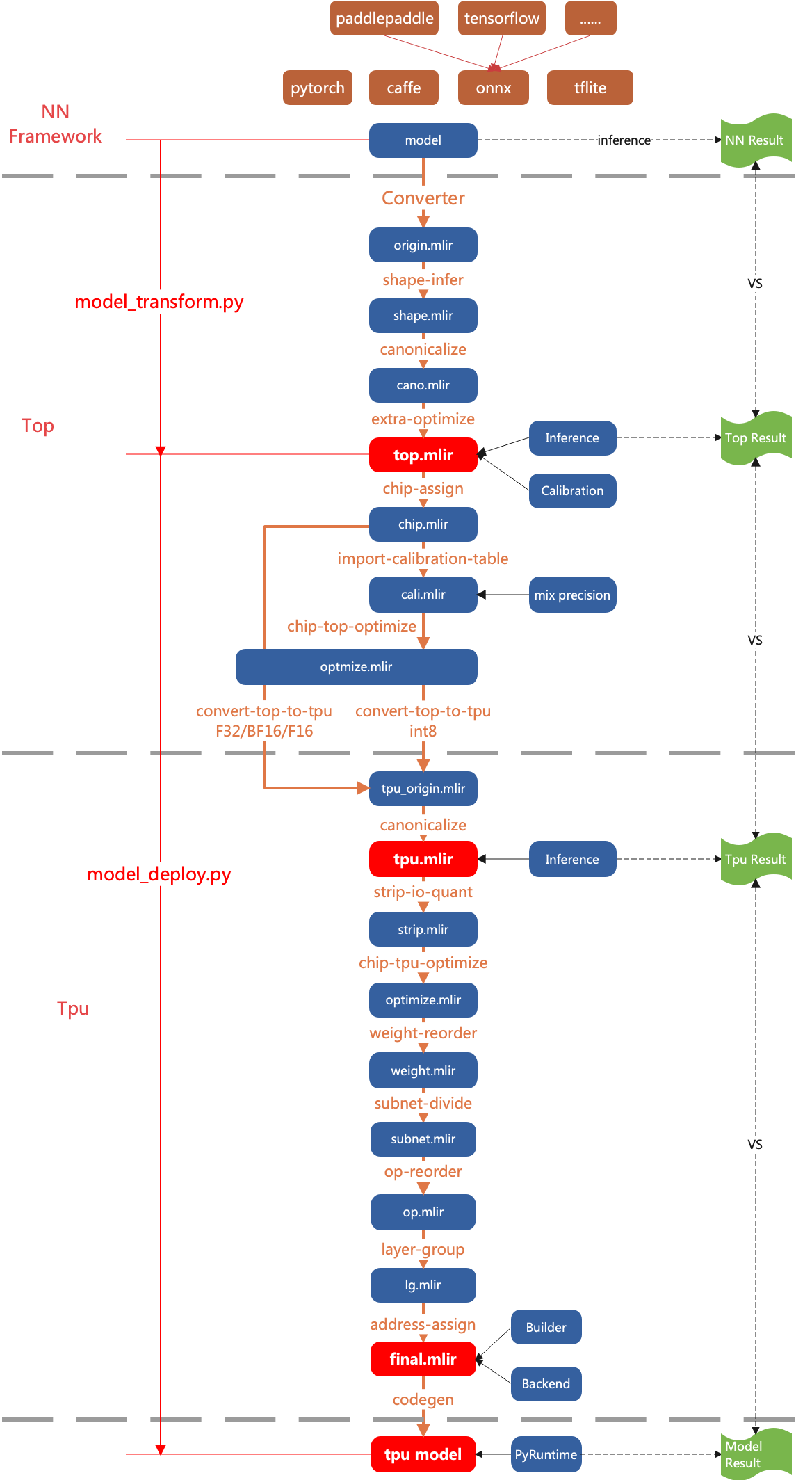
图 4.1 TPU-MLIR整体流程
4.2. Top Passes
- shape-infer
做shape推导, 包括常量折叠。对于shape不确定的op, 在这里确定shape。
- canonicalize
与具体op有关的图优化, 比如relu合并到conv、shape合并等等。
- extra-optimize
额外的pattern实现, 比如求FLOPs、去除无效输出等等。
- chip-assign
配置chip, 如bm1684x或者cv183x等等; 并根据chip对top层进行调整, 比如cv18xx将输入全部调整为F32。
- import-calibration-table
按照calibration table, 给每个op插入min和max, 用于后续量化; 对应对称量化则插入threshold
- chip-top-optimize
与chip相关的top层算子优化, 这是一个妥协, 有些top算子与chip具有相关性
- convert-top-to-tpu
将top层下层到tpu层; 如果是浮点类型(F32/F16/BF16), top层op基本上直接转换成相应的tpu层op即可; 如果是INT8类型, 则需要量化转换
4.3. Tpu Passes
- canonicalize
与tpu层具体op有关的图优化, 比如连续Requant的合并等等
- strip-io-quant
决定输入或输出是否是量化类型, 否则就是默认F32类型
- chip-tpu-optimize
与chip相关的tpu层算子优化
- weight-reorder
根据芯片特征对个别op的权重进行重新排列, 比如卷积的filter和bias
- subnet-divide
将网络按照TPU/CPU切分成不同的子网络, 如果所有算子都是TPU, 则子网络只有一个
- op-reorder
对op进行顺序调整, 让使用者离被使用者尽可能的靠近; 也有针对attention一类操作做特殊处理
- layer-group
对网络进行切分, 使尽可能多的op在local mem中连续计算
- address-assign
给需要global mem的op分配地址
- codegen
执行op的codegen接口, 生成cmdbuf。并用Builder模块采用flatbuffers格式生成最终的模型
4.4. Other Passes
还有一些可选的pass没有再图中标出来, 用于实现特定功能。
- fuse-preprocess
用于预处理融合, 对于图片类输入, 将图片的预处理过程合并到模型中
- add-postprocess
用于将ssd或yolo的后处理合并到模型中