TPU的工作模式
在算能的产品当中,根据主控单元(主机端Host)的不同,TPU对应有两种不同的运行模式,分别被称为PCIe模式和SOC模式。
PCIe模式:该模式下对应的产品形态为SC系列板卡。板卡通过PCIe接口连接到主机服务器上,主机服务器作为主控单元(Host)控制板卡的运行。
SoC模式:该模式下对应的产品形态为SE系列边缘推理设备。推理设备上的包含一个8核的A53处理器作为设备的主控单元(Host)控制板卡的运行。
TPU编程模型
由于TPU是一个异构的架构设计,由 主机端 发送指令,设备端 接收指令,按照指令执行指定的操作。 因此,驱动TPU的进行指定计算需要分别完成主机端和设备端的两部分代码:
主机端(Host): 主机端代码,运行在主机侧,发送控制TPU运行的命令。
设备端(Device): 设备端代码,运行在设备侧,通常调用TPU的各种指令运行相应的运算。
主机端和设备端的代码由于目标设备不同,因此需要使用不同的编译器对代码进行编译。
PCIe模式 下:
主机端代码编译器: 主机的本地C++编译器。
设备端代码编译器: 用于Linux ARM A53的交叉编译器。
SoC模式 下,代码在x86平台进行编译,在ARM A53平台运行。
主机端代码编译器: 用于Linux ARM A53交叉编译器。
设备端代码编译器: 用于Linux ARM A53交叉编译器。
上述Linux ARM A53交叉编译器,可以通过TPUKernel工具包内scripts/prepare_toolchain.sh脚本来进行下载
对于Device端代码,编译的过程可以被看作是动态链接库更新的过程,

如上图所示,device_*.c() 就是开发者完成的设备端代码,设备端代码编译器将设备端代码和原始的底库libbm1684x.a进行链接,形成完整的A53Lite可加载的原始动态库文件。
Host端
在完成了上述动态库的更新后,此时只需要加载动态库,然后在Host发送调用指令就可以控制TPU运行指定的计算。
typedef struct _param_func{
...
...
}__attribute__((packed)) param_func_0_1;
bm_handle_t handle;
param_func_0_1 param;
bm_dev_request(&handle, 0);
tpu_kernel_launch_sync(handle, "func_0_1", ¶m, sizeof(param));
bm_dev_free(&handle);

如上图所示,Device端固件中已经注册了 func_0_0() , func_0_1() , func_0_2() , func_1_0() , func_1_1() , func_1_2() …等函数,
主机端现在发送 func_0_1() ,就可以调动TPU进行 func_0_1() 的计算。
主机端调用TPU进行计算有 异步 和 同步 两种方式。
同步运行方式
同步运行方式 是指主机端在发送了调用计算命令后,不再继续下面代码的执行,直到TPU计算完成,继续进行主机端代码的执行。
主机端调用下面API后,便会等待TPU直到计算完成。
- bm_status_t tpu_kernel_launch_sync(bm_handle_t handle, const char *func_name, const void *args, unsigned int size)
Launch the kernel function on device synchronously.
- 参数:
handle – Handle of the device.
func_name – Name of the kernel function to launch on device.
args – Pointer to the user-discript data package.
size – Size of the user-discript data package in bytes.
- 返回:
Status of launching kernel function, BM_SUCCESS means succeeded, otherwise, some errors caught.
异步运行方式
异步运行方式 是指主机端在发送了调用指令后,继续执行后续的代码,TPU和主机端异步运行。
主机端在调用了下面API后,TPU就会开始计算,同时主机端仍会继续往下执行。
- bm_status_t tpu_kernel_launch_async(bm_handle_t handle, const char *func_name, const void *args, unsigned int size)
Launch the kernel function on device asynchronously.
- 参数:
handle – Handle of the device.
func_name – Name of the kernel function to launch on device.
args – Pointer to the user-discript data package.
size – Size of the user-discript data package in bytes.
- 返回:
Status of launching kernel function, BM_SUCCESS means succeeded, otherwise, some errors caught.
主机端可以通过下面的API来实现和TPU的同步,调用下面API后,主机端会等待TPU完成计算。
- bm_status_t tpu_kernel_sync(bm_handle_t handle)
Synchronize the device.
- 参数:
handle – Handle of the device.
- 返回:
Status of launching kernel function, BM_SUCCESS means succeeded, otherwise, some errors caught.
Device端
上一节中,介绍了用户是怎么样驱使TPU进行计算的。 在这一章节,我们将开始学习如何编写device端代码,利用TPU完成我们想要的计算,在此之前我们需要首先了解一下,TPU定义了哪些基本的指令。 在TPU架构一节,我们已经介绍了TPU的整个计算过程,回顾一下,计算过程可以划分为三部分:
1.数据在Host端内存和系统内存(System Memmory)之间的来回搬运。
2.数据在系统内存(System Memory)和Local Memory之间的来回搬运。
3.TPU对Local Memory中的数据进行相关计算。
“数据在Host端内存和系统内存之间的来回搬运”, 是主机端相关,这里不再涉及。由于数据存在于Host内存当中,因此这部分API通常由Host端来调用,关于Host端的相关命令可以参考上一小节。
指令系统
· GDMA指令
系统内存和Local-Memory中与数据搬运相关的操作都由GDMA指令完成。
与GDMA相关的指令都以 tpu_gdma_() 开头,包括数据在Local Memory之间的搬运、系统内存之间的搬运。
详细的指令说明和参数,参见“TPU_API”章节。
· BDC指令
TPU进行数据计算的相关操作都可以由BDC指令来完成。与BDC相关的指令都以 tpu_bdc_() 开头。
· HAU指令
一些不适用于并行加速计算的指令集,包括 NMS、SORT等。
内存与数据排列
· 数据的表示
Tensor
在TPU中,我们使用Tensor来描述数据。
Tensor 是一个4维数组,使用4元组(N,C,H,W)来描述一个Tensor的几何尺寸( Shape )。 Tensor(n, c, h, w)表示在(n,c,h,w)索引下的数据元素。
Stride 用于描述Tensor在实际内存当中是如何摆放,同样使用4元组(N_stride,C_stride,H_stride,W_stride)来描述, 表示 Tensor 在内存当中存放时,元素间间隔了多少元素,具体而言:
W_stride 描述的是从Tensor(n,c,h,w)到Tensor(n,c,h,w+1)两个元素之间,在内存存储时,间隔了多少个元素。
H_stride 描述的是从Tensor(n,c,h,w)到Tensor(n,c,h+1,w)两个元素之间,在内存存储时,间隔了多少个元素。
C_stride 描述的是从Tensor(n,c,h,w)到Tensor(n,c+X,h,w)两个元素之间,在内存存储时,间隔了多少个元素,X表示NPU的数量。
N_stride 描述的是从Tensor(n,c,h,w)到Tensor(n+1,c,h,w)两个元素之间,在内存存储时,间隔了多少个元素。
假设现在有一个Tensor,它的每一个元素都占1个byte,它的Shape是(4,3,2,2), 如果它的存储方式Stride是(12,4,2,1),在内存当中,它的排列方式就会如下图所示,

如果Tensor的存储方式Stride是(24,4,2,1),在内存当中,Tensor的排列方式就会如下所示,

如果Tensor的存储方式Stride是(24,8,4,2),在内存当中,Tensor的排列方式就会如下所示,

如果它的存储方式Stride是(24,8,4,1),在内存当中,Tensor的排列方式就会如下所示,

数据元素的类型
Stride 以元素个数作为计量单位。不同类型的数据元素占据不同的字节数, 在BM1684x设备上支持如下格式的数据类型:
· Tensor在global memory的排列方式
global memory 由一块DDR内存组成。
一个Shape为(N,C,H,W)的Tensor,在 global memory 排列,对应的Stride为:
W_Stride = 1,
H_Stride = W,
C_Stride = H*W,
N_Stride = C*H*W。
这种排列方式被称为 连续存储方式 。
举例: 一个Shape(N=2, C=2,H=3,W=2)的Tensor在global memory排列方式
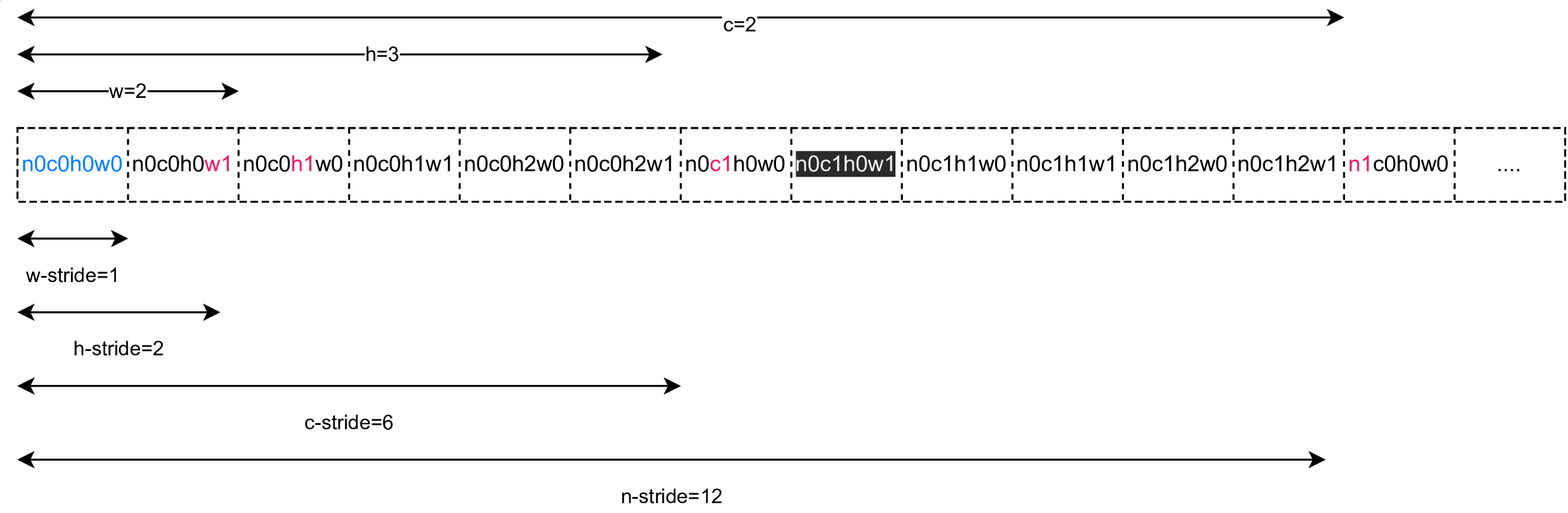
上图中,n0c0h0w0 代表 Tensor(0,0,0,0) 位置的元素。
· Tensor在local memory的排列方式
local memory的物理组成和地址分配
Local Memory共由多片SRAM(静态随机存取存储器)构成,每一片SRAM都被称为一个 Bank。
bm1684x设备一共由16个Bank构成。16个Bank组成整个 local memory。
整个Local Memory同时被划分为了64个 lane (对应64个NPU,以下用NPU指代lane),地址分配如下图所示:
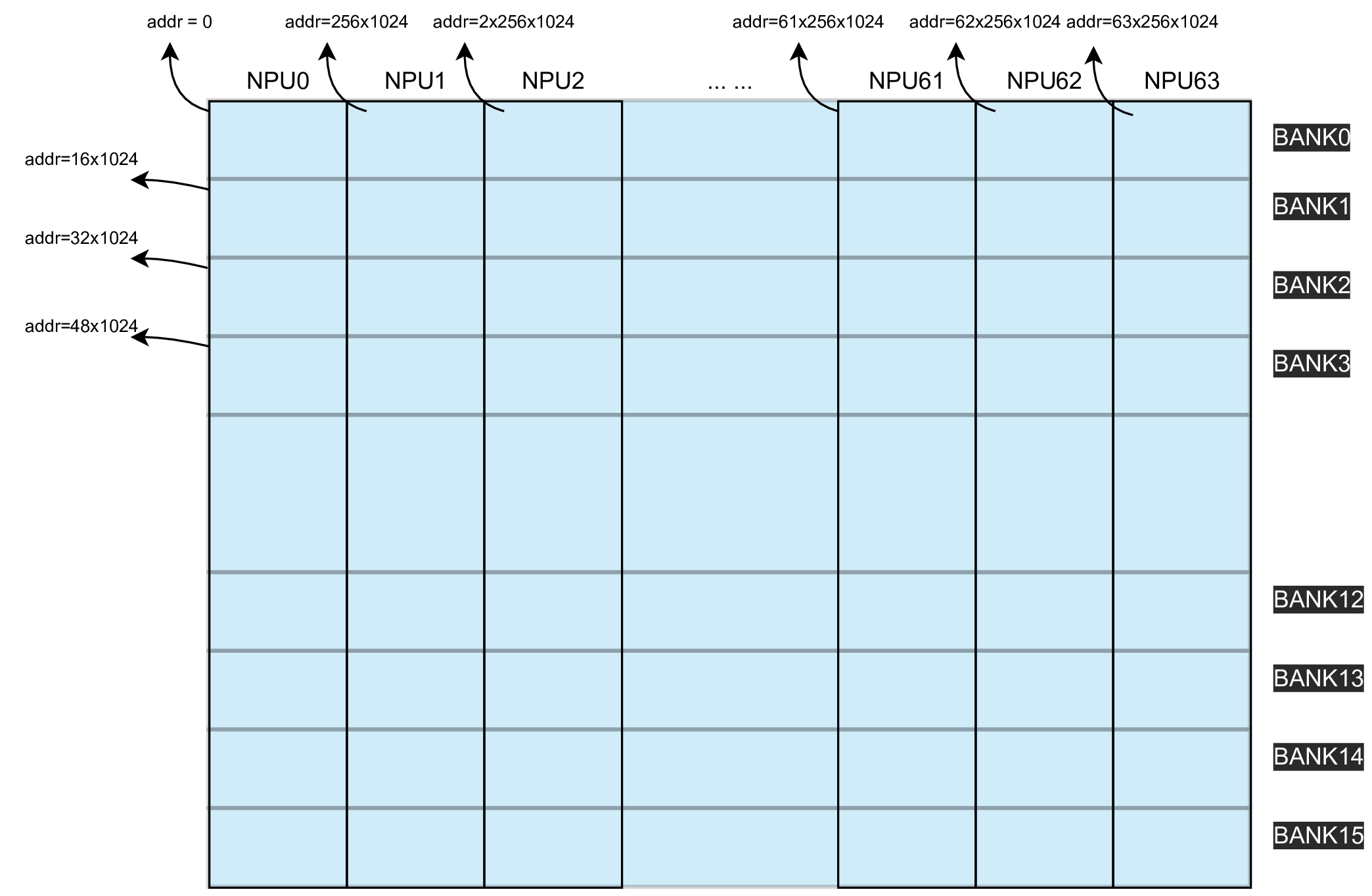
BM1684x的Local Memory大小为 256KB * 64,地址按照NPU进行分配, 其中,NPU0对应 0~256*1024-1 的地址,NPU1对应 256*1024~2*256*1024-1 的地址,依次类推。
Tensor在Local memory上排列的基本规则
Tensor在Local Memory上的排布方式与global Memory的排布方式不同,主要区别在于 C维度的数据排布方式。 一个Shape为(N,C,H,W)的Tensor,Tensor(N,c,H,W)代表:当C = c时,Tensor的数据切片。 对于不同的c, Tensor(N,c,H,W)分配在不同的NPU上。
举例,Tensor的Shape(N=2,C=3,H=2,W=3),Stride(N_stride = 9,C_stride = 9, H_stride = 3, W_stride = 1) 那么Tensor在Local Memory上的数据排列方式如下所示。

不同大小的C影响着实际存储方式,假设现在一共由X个NPU,考虑下面几种存储情形:
情形1: 当Tensor的Shape的维度C = X-1时,当Tensor从NPU0开始存储时,那么Tensor在Local Memory上的排布方式如下所示。
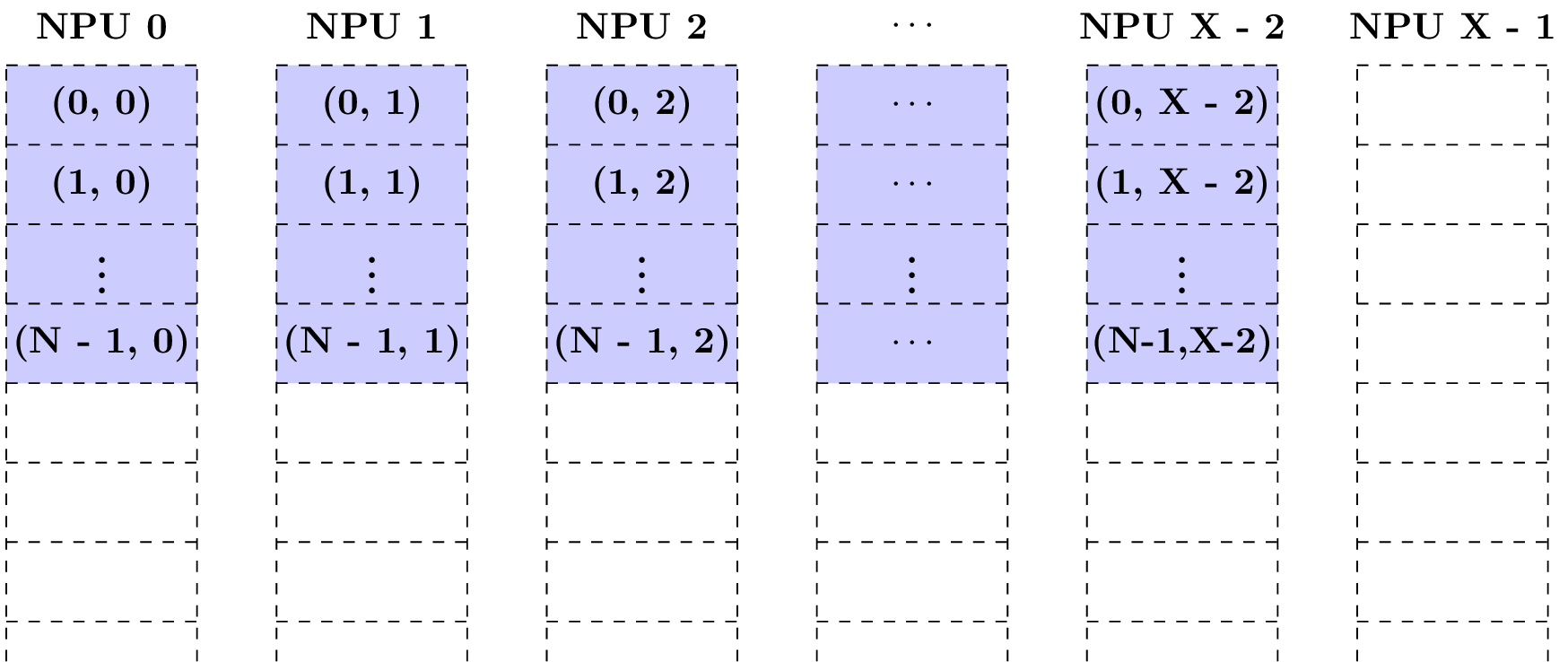
在NPU X-1的地址空间,没有数据分布。
情形2: 当Tensor的Shape的维度C = X-1时,当Tensor从NPU1开始存储时,那么Tensor在Local Memory上的排布方式如下所示。

在NPU0的地址空间,没有数据分布。
情形3: 当Tensor的Shape的维度C = X + 2,当Tensor从NPU0开始存储时,那么Tensor在Local Memory上的排布方式如下所示。
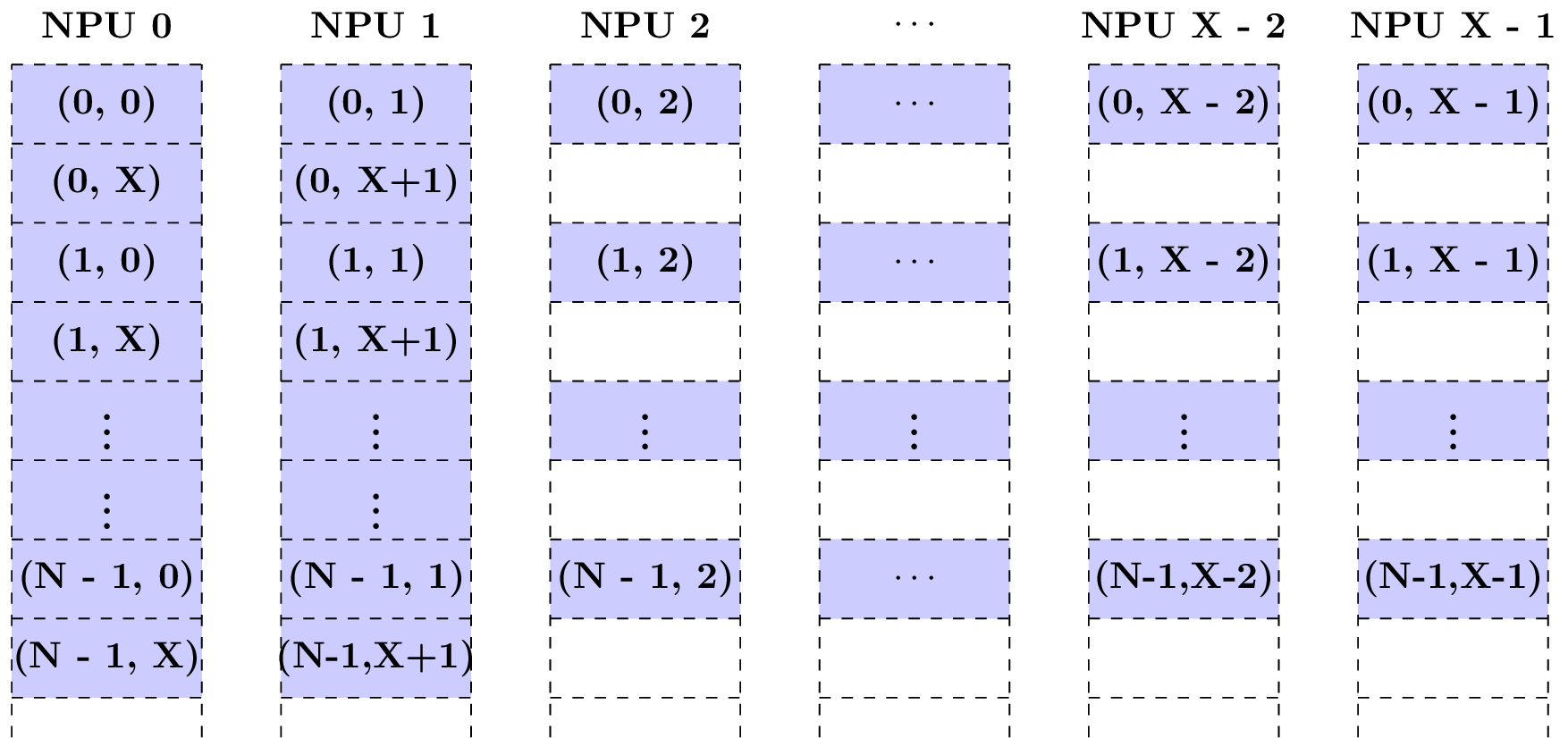
C=X+1维度的数据被排布到NPU0,而C=X+2维度的数据被排布到NPU1。并且注意到,下一个N维度仍然从NPU0开始排布。
情形4: 当Tensor的Shape的维度C= X + 2, 而Tensor从NPU X-1 开始存储时,那么Tensor在Local Memory上的排布方式如下所示。
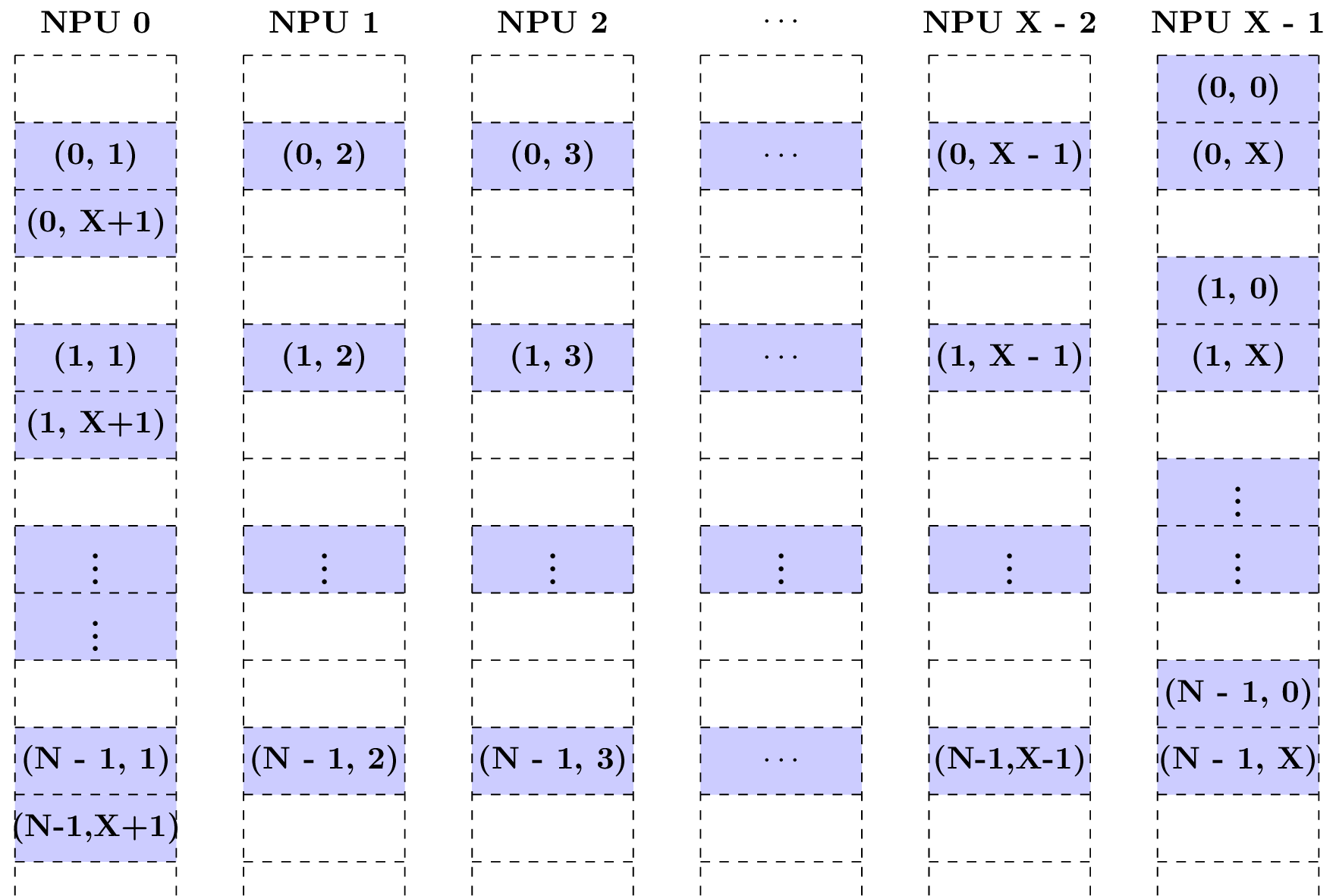
可以看到, C=0维度的数据被排布到了NPU X-1, C=1维度的数据被排布到了NPU0上,依次类推,C= X+2维度的数据被排布到了NPU0上。
Local Memory上几种常用数据排布方式
上面介绍了Tensor在Local Memory上存储的基本原则,现在介绍1684x指令集常用的几种数据排布方式:
1. 64-Bytes对齐存储方式
“64-Bytes对齐存储方式”是最常用的Tensor存储方式,它是指Tensor排放存储要满足以下几个约束:
Tensor的起始地址是64的整数倍
W_stride = 1
H_stride = W
C_stride = ceil(H*W, 16) * 16, 如果数据元素是 32-bits ; ceil(H*W, 32) * 32, 如果数据元素是 16-bits ; ceil(H*W, 64) * 64, 如果数据元素是 8-bits。
N_stride = C_stride * (单个NPU上channel的个数)
其中 ceil 是向上取整的意思。可通过 tpu_aligned_stride() 计算 stride。
为举例简便,假设NPU个数=4
举例1: Tensor的Shape(.N=2,.C=3,.H=4,.W=5),数据类型为float16, NPU0开始存储

举例2: Tensor的Shape(.N=2,.C=3,.H=4,.W=5),数据类型为float16,NPU2开始存储

2. 紧凑存储方式
“紧凑存储方式”也是较为常用的Tensor存储方式。
假设Tensor的Shape为(N,C,H,W),按照“紧凑存储方式存储”要满足以下约束:
Tensor的起始地址是4的整数倍。
W_stride = 1
H_stride = W
C_stride = H * W
N_stride = C_stride * (单个NPU上channel的个数)
可通过 tpu_compact_stride() 计算 stride。
为举例简便,假设NPU个数=4
举例1: Tensor的Shape(.N=2,.C=3,.H=4,.W=5),数据类型为float16, NPU0开始存储

举例2: Tensor的Shape(.N=2,.C=3,.H=4,.W=5),数据类型为float16,NPU2开始存储

3. 矩阵存储方式
“矩阵存储方式”是 矩阵运算指令 用的数据存储方式。
对于一个n x m的矩阵,可以用Tensor的4维数组的形式来进行表示, 这个Tensor的Shape为(N=n,C=ceil(m/w),H=1,W=w),其中w可以为(1,m)之间的任意值。
为举例简便,假设NPU个数=4
举例1:矩阵的形状为(2x40),数据类型为float16, w = 40

举例2:矩阵的形状为(2x40),数据类型为float16, w = 20

举例3:矩阵的形状为(2x40),数据类型为float16, w = 15

举例4:矩阵的形状为(2x40),数据类型为float16, w = 8

举例5:矩阵的形状为(2x40),数据类型为float16, w = 6

4. 向量存储
对于一个1 x m的向量,可以用Tensor的4维数组的形式来进行表示, 这个Tensor的Shape为(N=1,C=ceil(m/w),H=1,W=w),其中w可以为(1,m)之间的任意值。
5. 行64字节对齐存储
一种 4D 张量在 local memory 中的存储格式。张量的 shape 是 (N, C, H, W),满足
地址被 64 整除
W-stride 是 1
H-stride 是 ceil(W / 16) * 16,如果元素的数据类型的位宽是 32-bit, ceil(W / 32) * 32,如果是 16-bit,ceil(W / 64) * 64,如果是 8-bit
C-stride 是 H * H-stride
N-stride 是 C-stride 乘以每个 NPU 的 channel 数
可通过 tpu_line_aligned_stride() 计算 stride。
6. 64IC/32IC 存储
64IC/32IC 存储是卷积核在 local memory 中的特殊存储方式,仅用于卷积计算过程。其中 INT8 kernel 以 64IC 格式存放, FP16/BFP16 kernel 以 32IC 格式存放。
假设卷积核的 shape 是 (ic, oc, kh, kw),分别表示 input channel、 output channel、 卷积核的高度以及卷积核的宽度。
64IC 存储满足:
W_stride = 64
H_stride = 64 * kw
C_stride = 64 * kw * kh * ceil(ic/64)
N_stride = 64 * kw * kh * ceil(ic/64)
其中,每 64 个 input channel 作为一组进行存储,每组之间的 stride 为 64 * kw * kh。
32IC 存储满足:
W_stride = 32
H_stride = 32 * kw
C_stride = 32 * kw * kh * ceil(ic/32)
N_stride = 32 * kw * kh * ceil(ic/32)
其中,每 32 个 input channel 作为一组进行存储,每组之间的 stride 为 32 * kw * kh。