5. 量化步骤¶
对于常见以图片作为输入的CV类推理网络,推荐使用auto_cali一键量化工具。这个工具是分步量化的整合,操作更加简单,可以减少分步量化过程中手工输入引起的错误等,其功能如下:
一键完成从原始框架(TensorFlow/PyTorch/Caffe/Darknet/MxNet/PaddlePaddle/ONNX)到BM1684芯片bmodel的转换
可根据预设的优化参数组合根据int8模型精度结果自动进行量化策略搜索,找到满足精度要求的最佳量化策略
以下章节将以量化Caffe框架下的MobilenetSSD网络为例,说明一键量化工具和其中包含的各个步骤分别完成的功能。
5.1. auto_cali一键量化工具¶
使用bmnnsdk2-bm1684_vX.X.X发布包启动docker环境后,进入模型以及量化数据集存放目录。 此处以caffe模型为例:进入/workspace/examples/calibration/auto_cali目录:
5.1.1. 量化用数据集类型可二选一:¶
lmdb:制作方法可参考: 准备lmdb数据集
原始图片
5.1.2. Caffe框架下的MobileNet SSD一键量化¶
ufw.cali.cali_model模块可一键完成从原始框架到1684芯片的bmodel的量化转换
$ python3 -m ufw.cali.cali_model \ --net_name 'MobilenetSSD' \ --model ./test_models/caffe/MobileNetSSD_deploy.prototxt \ --weight ./test_models/caffe/MobileNetSSD_deploy.caffemodel \ --cali_image_path ./test_models/detect_pic/ \ #使用原始图片, 若使用lmdb数据配置参数:cali_lmdb --cali_image_preprocess='resize_h=512,resize_w=512;mean_value=127.5:127.5:127.5, scale=0.007843' \ --input_shapes '(1,3,512,512)'
可选参数说明
--net_name: 模型/网络的名字,此名字会用于生成的umodel的文件名 --model: 模型文件路径,tensorflow的pb文件、pytorch的pt文件、mxnet的json文件、caffe和U-FrameWork中prototxt文件 --weights: 模型weights文件路径,caffe中caffemodel文件、U-FrameWork中fp32umodel文件、mxnet中params文件 --input_names: 网络输入tensor名,格式如:’(input_tensor1_name); (input_tensor2_name)',中间以分号分割 --input_shapes: 网络输入tensor名,格式如:’(input_tensor1_name); (input_tensor2_name)',中间以分号分割,如果有输入名,需要和输入名对应 --output_names: 网络输出tensor名,格式如:’output_tensor1_name; output_tensor2_name ',中间以分号分割 --cali_lmdb: 量化校准图片集lmdb文件路径,默认为空串,若不设置,则要求设置cali_image_path从文件目录中读取校准图片 --cali_image_path: 量化校准图片集目录,默认为空串,若不设置,则要求设置cali_lmdb从lmdb中读取校准数据 --cali_iterations: 量化校准图片数量,默认值为0表示从lmdb或图片目录中获取真实数量,可以设置小于实际数量的图片数,一般推荐使用200张图片校准 --cali_image_preprocess: 预定义的图片预处理模板或者用户自定义的预处理,预定义处理包括:vgg_tensorflow,ssd_vgg_tensorflow,ssd_inception_tensorflow,如果不是这些预处理模板,则输入自定义的预处理字符串,可以仿照help中打印的预处理模板修改 例如: --cali_image_preprocess vgg_tensorflow,使用vgg_tensorflow预处理模板,或者 --cali_image_preprocess 'resize_side=256;crop_h=224,crop_w=224;mean_value=103.94:116.78:123.68,scale=1.0,bgr2rgb=True' --fp32_layer_list: 指定某些层固定采用fp32计算,按格式:"层1名,层2名,......,层n名"指定,用逗号分隔 --layer_param_list: 可对层的layer_param进行设置,层之间用';'分号分割,层名和层参数用':'冒号分割,层的各个参数间用','逗号分隔,参数名和值用'='分隔,比如:层1名:参数1=1,参数2=xx;层2名:参数1=3,参数2=yy --convert_bmodel_cmd_opt: 指定输出bmodel的命令参数,提供给bmnetu使用,默认为空,可使用bmnetu --help查看支持的选项,比如:配置为’-dyn 1 -opt 2 -enable_profile‘,会直接将这3个参数传给bmnetu命令
自动量化参数说明
开启以下参数,可以在一定程度上尝试用不同的量化选项测试量化效果,选优提高量化精度。量化效果目前是以浮点网络的输出和定点网络的输出的余弦距离作为判断依据(因为网络形式多种多样,这个标准并非绝对准确,量化选优还是以实际部署后的真实环境测试结果为准)。 Auto-cali自动量化会自动进行一些尝试,所以会循环进行量化和测试精度的过程,叠加每次进行多次iteration的推理,可能会进行很长时间,用户也可根据经验自行分步量化。
--postprocess_and_calc_score_class: 指定auto_cali/usr目录下文件作为网络后处理和精度计算的类,默认为:支持分类模型的topx_accuracy_for_classify,当前支持:[detect_accuracy、topx_accuracy_for_classify、feature_similarity、None],即:支持目标检测模型的detect_accuracy、支持对提取特征进行cos相似度计算的feature_similarity;若设置None,表示不进行任何后处理和精度计算 --try_cali_accuracy_opt: 直接指定calibration工具的量化参数,不再使用自动搜素的量化参数,默认为空串,方便调试用,可使用calibration_use_pb --help查看支持的选项;可以指定为default,此时就完全使用默认calibration_use_pb最基本默认参数进行测试,方便基本调试 例如: --try_cali_accuracy_opt='-per_channel=true,-th_method=SYMKL' --test_iterations: 测试集上测试的迭代数,默认为0表示从lmdb或图片目录中获取真实数量, 可以设置小于实际数量的图片数;若是网络发送测试数据方式,则必须设置该参数 --test_batch_size: 测试集上测试推理的batch大小 --feature_compare_layer_list: 有时候网络的输出不适合作为余弦距离比较标准,可以用此参数指定用来比较余弦距离的层 --not_suspend: 在自动搜索提高精度时候遇到warnning不退出 --only_test_int8_acccury: 设为True时只对当前int8模型进行精度测试
5.1.3. auto_cali一键量化结果:¶
生成芯片端运行的可执行文件:compilation.bmodel
量化质量评估,可参考 view-demo
如量化精度不满足需求,自动搜索或手工配置量化策略可参考 量化技巧
Auto-cali一键量化作为一套合并多个步骤的量化接口,如果用户想在其基础上进一步调优或者一键量化不能满足要求,用户可以分步执行量化,在每个步骤中进行定制和尝试,以下是分步量化的进一步描述。
5.2. 准备lmdb数据集¶
Quantization-tools对输入数据的格式要求是[N,C,H,W] (即先按照W存放数据,再按照H存放数据,依次类推)
Quantization-tools对输入数据的C维度的存放顺序与原始框架保持一致。例如caffe框架要求的C维度存放顺序是BGR;tensorflow要求的C维度存放顺序是RGB
需要将图片转换成lmdb格式的才能进行量化。 将数据转换成lmdb数据集有两种方法:
使用上述 auto_cali一键量化工具 工具,将图片目录转化为lmdb供分步量化使用。
运用U-FrameWork接口,在网络推理过程中或编写脚本将网络推理输入抓取存成lmdb,方法请参考 create_lmdb
在U-FrameWork中,网络的输入数据使用LMDB形式保存,作为data layer的数据来源。对于一般简单的情况,只需将量化输入图片进行解码和格式转换就可以了, 推荐在制作LMDB过程中即进行减均值除方差等操作,lmdb中保存前处理后的数据。而对于前处理不能精确表达的复杂处理, 或者在级联网络中需要把中间结果作为下一级网络的输入进行训练的情况,用户可以自己开发预处理脚本,直接生成lmdb。
与LMDB相关的功能已经独立成为ufwio包,该安装包不再依赖Sophgo的SDK,可以在任何Python3.5及以上环境下运行。
LMDB API组成
lmdb = ufwio.LMDB_Dataset(path, queuesize=100, mapsize=20e6) # 建立一个 LMDBDataset对象,
path: 建立LMDB的路径(会自建文件夹,并将数据内容存储在文件夹下的data.mdb) queuesize: 缓存队列,指缓存图片数据的个数。默认为100,增加该数值会提高读写性能,但是对内存消耗较大 mapsize: LMDB建立时开辟的内存空间,LMDBDataset会在内存映射不够的时候自动翻倍
put(data, labels=None, keys=None) # 存储图片和标签信息
data: tensor数据,只接受numpay.array格式或是含多个numpy.array的python list。数据类型可以是int8/uint8/int16/uint16/int32/uint32/float32。数据会 以原始shape存储。 lables: 图片的lable,需要是int类型,如果没有label不填该值即可。 keys: LMDB的键值,可以使用原始图片的文件名,但是需要注意LMDB数据会对存储的数据按键值进行排序,推荐使用唯一且递增的键值。如果不填该值,LMDB_Dataset会自动维护一个递增的键值。
close()
将缓存取内容存储,并关闭数据集。如果不使用该方法,程序会在结束的时候自动执行该方法。 但是如果python解释器崩溃,则会导致缓存区数据丢失。
with Blocks
LMDB_Dataset支持使用python with语法管理资源。
LMDB API使用方式
import ufwio
txn = ufwio.LMDB_Dataset(‘to/your/path’)
txn.put(images) # 放置在循环中
在pytorch和tensorflow中,images通常是xxx.Tensor,可以使用images.numpy(),将其转化为numpy.array格式
txn.close()
示例代码
使用对象方法存储数据
import ufwio import torch images = torch.randn([1, 3,100,100]) path = "test_01" txn = ufwio.LMDB_Dataset(path) for i in range(1020): txn.put(images.numpy()) txn.close()
使用with语法来管理存储过程
import ufwio import torch images = torch.randn([1, 3,100,100]) path = "test_02" with ufwio.LMDB_Dataset(path) as db: for i in range(1024): db.put(images.numpy())
读取lmdb数据
import ufwio path = "test_02" for key, arr in ufwio.lmdb_data(path): print("{0} : {1}".format(key, arr)) # arr is an numpy.array
命令行查看lmdb内容
python3 -m ufwio.lmdb_info /path/to/your/LMDB/path
注意事项
此功能不会检查给定路径下是否已有文件,如果之前存在LMDB文件,直接往里添加新的内容往往会因为key重复等造成混乱,建议每次调用此功能前先将目标LMDB删除重新创建和添加。
使用重复的key会导致数据覆盖或污染,使用非递增的key会导致写入性能下降。
解析该LMDB的时候需要使用Data layer。
BMNNSDK工具包中也包含了创建lmdb的示例程序: 示例2:create_lmdb_demo 。此示例程序可以直接作为工具使用也可以在其基础上修改加入自定义的预处理。
如何使用生成的lmdb在 使用lmdb数据集 中描述,配合其中描述的前处理为量化期间的推理准备好数据。
5.3. 生成fp32umodel¶
为了将第三方框架训练后的网络量化,需要先将它们转化为fp32umodel。本阶段会生成一个*.fp32umodel文件以及一个*.prototxt文件。 prototxt文件的文件名一般是net_name_bmnetX_test_fp32.prototxt,其中X代表原始框架名的首字母, 比如Tensorflow的网络转为umodel后prototxt文件名会是net_name_bmnett_test_fp32.prototxt,PyTorch转换的网络会是net_name_bmnetp_test_fp32.prototxt等。 此阶段生成的fp32umodel文件是量化的输入, 使用lmdb数据集 中修改预处理就是针对此阶段生成的prototxt文件的修改。
注意 :基于精度方面考虑输入Calibration-tools的fp32umodel一般需要保持Batchnorm层以及 Scale层独立。有时候客户可能会利用第三方工具对网络图做一些等价转换,这个过程中请 确保Batchnorm层以及Scale层不被提前融合到Convolution。
转换生成fp32umodel的工具为一系列名为ufw.tools.*_to_umodel的python脚本,存放于ufw包中,*号代表不同框架的缩写。可以通过以下命令查看使用帮助:
python3 -m ufw.tools.cf_to_umodel --help # Caffe模型转化fp32umodel工具 python3 -m ufw.tools.pt_to_umodel --help # PyTorch模型转化fp32umodel工具 python3 -m ufw.tools.tf_to_umodel --help # TensorFlow模型转化fp32umodel工具 python3 -m ufw.tools.dn_to_umodel --help # Darknet模型转化fp32umodel工具 python3 -m ufw.tools.mx_to_umodel --help # MxNet模型转化fp32umodel工具 python3 -m ufw.tools.on_to_umodel --help # ONNX模型转化fp32umodel工具 python3 -m ufw.tools.pp_to_umodel --help # PaddlePaddle模型转化fp32umdoel工具
详细参数说明针对不同框架可能稍有区别,具体参考下文示例中各框架下的参数解释。
以下示例中模型生成命令已经保存为简单的python脚本,用户可以在这些脚本的基础上修改其中的少量参数完成自己的模型转换,也可以 在命令行直接使用python3 -m ufw.tools.xx_to_umodel加参数进行转换。
5.3.1. Caffe框架下的网络模型生成fp32umodel¶
本例以附录2中附带的 示例5:caffemodel_to_fp32umodel_demo 来说明转化过程和执行过程。
参数修改
示例脚本存放于BmnnSDK发布目录的examples/calibration/caffemodel_to_fp32umodel_demo/ resnet50_to_umodel.py 中,对于用户网络,可以以此为基础,修改其中的-m -w -s 参数:
1import ufw.tools as tools 2 3cf_resnet50 = [ 4 '-m', './models/ResNet-50-test.prototxt', 5 '-w', './models/ResNet-50-model.caffemodel', 6 '-s', '(1,3,224,224)', 7 '-d', 'compilation', 8 '-n', 'resnet-50', 9 '--cmp' 10] 11 12if __name__ == '__main__': 13 tools.cf_to_umodel(cf_resnet50)可选参数解释 -m #指向*.prototxt文件的路径 -w #指向*.caffemodel文件的路径 -s #输入blob的维度,(N,C,H,W) -d #输出文件夹的名字 -n #网络名字 --cmp #可选参数,指定是否测试模型转化的中间文件 --dyn #可选参数,指定是否以动态网络类型转换模型
运行命令:
例如: 调用转换脚本:python3 resnet50_to_umodel.py 或者自行配置转换参数:python3 -m ufw.tools.cf_to_umodel \ -m './models/ResNet-50-test.prototxt' \ -w './models/ResNet-50-model.caffemodel' \ -s '(1,3,224,224)' \ -d 'compilation' \ -n 'resnet-50' \ --cmp
输出:
若不指定-d参数,则在当前文件夹下,默认新生成compilation文件夹用来存放输出的*.fp32umodel 与 *_bmnetc_test_fp32.prototxt。
5.3.2. Tensorflow框架下的网络模型生成fp32umodel¶
参数修改
示例可以参考 示例6:tf_to_fp32umodel_demo 中的脚本,存放于BmnnSDK发布目录examples/calibration/tf_to_fp32umodel_demo/ resnet50_v2_to_umodel.py,修改其中的-m,-i,-s等 参数:
1import ufw.tools as tools 2 3tf_resnet50 = [ 4 '-m', './models/frozen_resnet_v2_50.pb', 5 '-i', 'input', 6 '-o', 'resnet_v2_50/predictions/Softmax', 7 '-s', '(1, 299, 299, 3)', 8 '-d', 'compilation', 9 '-n', 'resnet50_v2', 10 '-D', '../classify_demo/lmdb/imagenet_s/ilsvrc12_val_lmdb_with_preprocess', 11 '--cmp' 12] 13 14if __name__ == '__main__': 15 tools.tf_to_umodel(tf_resnet50)
可选参数解释 -m #指向*.pb文件的路径 -i #输入tensor的名称,多输入以逗号分隔,比如:"input_ids,input_mask,segment_ids" -o #输出tensor的名称 -s #输入tensor的维度,(N,H,W,C),多输入网络以逗号分隔,需要和输入的顺序一致,比如:"[1,384],[1,384],[1,384]" -d #输出文件夹的名字 -n #网络的名字 -D #lmdb数据集的位置, #没有的话,可以不设置此参数,然后在手动编辑prototxt文件的时候,根据实际的路径来添加 --cmp #可选参数,指定是否测试模型转化的中间文件 --dyn #可选参数,指定是否以动态网络类型转换模型 --descs #可选参数,根据原始模型可能需要输入的数据类型等描述信息,比如 "[0,uint8,0,256]",多个输入之间用","分隔,比如:"[0,int32,0,256],[1, int32, 0, 2],[2, int32, 0, 2]"
运行命令:
例如: 调用转换脚本:python3 resnet50_v2_to_umodel.py 或者自行配置转换参数:python3 -m ufw.tools.tf_to_umodel \ -m './models/frozen_resnet_v2_50.pb' \ -i 'input' \ -o 'resnet_v2_50/predictions/Softmax' \ -s '(1, 299, 299, 3)' \ -d 'compilation' \ -n 'resnet50_v2' \ -D '../classify_demo/lmdb/imagenet_s/ilsvrc12_val_lmdb_with_preprocess' \ --cmp
输出:
若不指定-d参数,则在当前文件夹下,默认新生成compilation文件夹存放输出的*.fp32umodel 与*_bmnett_test_fp32.prototxt。
5.3.3. Pytorch框架下的网络模型生成fp32umodel¶
参数修改
以BmnnSDK发布目录下examples/calibration/pt_to_fp32umodel_demo/mobilenet_v2_to_umodel.py为基础,修改其中的-m,-s等 参数。
1import ufw.tools as tools 2 3pt_mobilenet = [ 4 '-m', './models/mobilenet_v2.pt', 5 '-s', '(1,3,224,224)', 6 '-d', 'compilation', 7 '-D', '../classify_demo/lmdb/imagenet_s/ilsvrc12_val_lmdb_with_preprocess', 8 '--cmp' 9] 10 11if __name__ == '__main__': 12 tools.pt_to_umodel(pt_mobilenet)可选参数解释 -m #指向*.pb文件的路径 -s #输入tensor的维度,(N,C,H,W) -D #lmdb数据集的位置, #没有的话,可以不设置此参数,然后在手动编辑prototxt文件的时候,根据实际的路径来添加 --cmp #可选参数,指定是否测试模型转化的中间文件 --dyn #可选参数,指定是否以动态网络类型转换模型 --descs #可选参数,根据原始模型可能需要输入的数据类型等描述信息,比如 "[0,uint8,0,256]",多个输入之间用","分隔
运行命令:
例如: 调用转换脚本:python3 mobilenet_v2_to_umodel.py 或者自行配置转换参数:python3 -m ufw.tools.pt_to_umodel \ -m './models/mobilenet_v2.pt' \ -s '(1,3,224,224)' \ -d 'compilation' \ -D '../classify_demo/lmdb/imagenet_s/ilsvrc12_val_lmdb_with_preprocess' \ --cmp
输出:
若不指定-d参数,则在当前文件夹下,默认新生成compilation文件夹存放输出的 *.fp32umodel 与 *_bmnetp_test_fp32.prototxt
5.3.4. Mxnet框架下的网络模型生成fp32umodel¶
参数修改
以BmnnSDK发布目录下examples/calibration/mx_to_fp32umodel_demo/mobilenet0.25_to_umodel.py 为基础,修改其中的-m,-w,-s等 参数:
1import ufw.tools as tools 2 3mx_mobilenet = [ 4 '-m', './models/mobilenet0.25-symbol.json', 5 '-w', './models/mobilenet0.25-0000.params', 6 '-s', '(1,3,128,128)', 7 '-d', 'compilation', 8 '-D', '../classify_demo/lmdb/imagenet_s/ilsvrc12_val_lmdb_with_preprocess', 9 '--cmp' 10] 11 12if __name__ == '__main__': 13 tools.mx_to_umodel(mx_mobilenet)
参数解释 -m #指向*.json文件的路径 -w #指向*params文件的路径 -s #输入tensor的维度,(N,C,H,W) -D #lmdb数据集的位置, #没有的话,可以不设置此参数,然后在手动编辑prototxt文件的时候,根据实际的路径来添加 --cmp #可选参数,指定是否测试模型转化的中间文件
运行命令:
例如: 调用转换脚本:python3 mobilenet0.25_to_umodel.py 或者自行配置转换参数:python3 -m ufw.tools.mx_to_umodel \ -m './models/mobilenet0.25-symbol.json' \ -w './models/mobilenet0.25-0000.params' \ -s '(1,3,128,128)' \ -d 'compilation' \ -D '../classify_demo/lmdb/imagenet_s/ilsvrc12_val_lmdb_with_preprocess' \ --cmp
输出:
若不指定-d参数,则在当前文件夹下,默认新生成compilation文件夹存放输出的 *.fp32umodel 与 *_bmnetm_test_fp32.prototxt。
5.3.5. Darknet框架下的网络模型生成fp32umodel¶
参数修改
以BmnnSDK发布目录下examples/calibration/dn_to_fp32umodel_demo/yolov3_to_umodel.py为 基础,修改其中的-m,-w,-s等 参数:
1import ufw.tools as tools 2 3dn_darknet = [ 4 '-m', './models/yolov3.cfg', 5 '-w', './models/yolov3.weights', 6 '-s', '[[1,3,416,416]]', 7 '-d', 'compilation' 8] 9 10if __name__ == '__main__': 11 tools.dn_to_umodel(dn_darknet)
参数解释 -m #指向*.cfg文件的路径 -w #指向*.weights文件的路径 -s #输入tensor的维度,(N,C,H,W) -d #生成umodel的文件夹 -D #lmdb数据集的位置, #没有的话,可以不设置此参数,然后在手动编辑prototxt文件的时候,根据实际的路径来添加 --cmp #可选参数,指定是否测试模型转化的中间文件
运行命令:
此示例程序发布时为了减少发布包体积,原始网络没有随SDK一块发布,要运行此示例需要先下载原始网络:
get_model.sh # download model 调用转换脚本:python3 yolov3_to_umodel.py 或者自行配置转换参数:python3 -m ufw.tools.dn_to_umodel \ -m './models/yolov3.cfg' \ -w './models/yolov3.weights' \ -s '[[1,3,416,416]]' \ -d 'compilation'
输出:
若不指定-d参数,则在当前文件夹下,默认新生成compilation文件夹存放输出的 *.fp32umodel 与 *_bmnetd_test_fp32.prototxt。
5.3.6. ONNX网络模型生成fp32umodel¶
参数修改
以BmnnSDK发布目录下examples/calibration/on_to_fp32umodel_demo/postnet_to_umodel.py为 基础,修改其中的-m,-i,-s等 参数:
1import ufw.tools as tools 2 3on_postnet = [ 4 '-m', './models/postnet.onnx', 5 '-s', '[(1, 80, 256)]', 6 '-i', '[mel_outputs]', 7 '-d', 'compilation', 8 '--cmp' 9] 10 11if __name__ == '__main__': 12 tools.on_to_umodel(on_postnet)
参数解释 -m #指向*.onnx文件的路径 -i #输入tensor的名称,多输入以逗号分隔,比如:"input_ids,input_mask,segment_ids" -s #输入tensor的维度,(N,C,H,W),多输入网络以逗号分隔,需要和输入tensor的名称的顺序一致,比如:"[1,384],[1,384],[1,384]" -o #输出tensor的名称 -d #生成umodel的文件夹 -D #lmdb数据集的位置, #没有的话,可以不设置此参数,然后在手动编辑prototxt文件的时候,根据实际的路径来添加 --cmp #可选参数,指定是否测试模型转化的中间文件 --descs #可选参数,根据原始模型可能需要输入的数据类型等描述信息,比如 "[0,uint8,0,256]",多个输入之间用","分隔,比如:"[0,int32,0,256],[1, int32, 0, 2],[2, int32, 0, 2]"
运行命令:
调用转换脚本:python3 postnet_to_umodel.py 或者自行配置转换参数:python3 -m ufw.tools.on_to_umodel \ -m './models/postnet.onnx' \ -s '[(1, 80, 256)]' \ -i '[mel_outputs]' \ -d 'compilation' \ --cmp
输出:
若不指定-d参数,则在当前文件夹下,默认新生成compilation文件夹存放输出的 *.fp32umodel 与 *_bmneto_test_fp32.prototxt。
5.3.7. PaddlePaddle网络模型生成fp32umodel¶
参数修改
以BmnnSDK发布目录下examples/calibration/pp_to_fp32umodel_demo/ppocr_rec_to_umodel.py为 基础,修改其中的-m,-i,-s等 参数:
1import ufw.tools as tools 2 3ppocr_rec = [ 4 '-m', './models/ppocr_mobile_v2.0_rec', 5 '-s', '[(1,3,32,100)]', 6 '-i', '[x]', 7 '-o', '[save_infer_model/scale_0.tmp_1]', 8 '-d', 'compilation', 9 '--cmp' 10] 11 12if __name__ == '__main__': 13 tools.pp_to_umodel(ppocr_rec)
参数解释 -m #指向*.pdiparams文件所在的路径 -s #输入tensor的维度,(N,C,H,W) -i #输入tensor的名称 -o #输出tensor的名称 -d #生成umodel的文件夹 --cmp #可选参数,指定是否测试模型转化的中间文件
运行命令:
调用转换脚本:python3 ppocr_rec_to_umodel.py 或者自行配置转换参数:python3 -m ufw.tools.pp_to_umodel \ -m './models/ppocr_mobile_v2.0_rec' \ -s '[(1, 3,32,100)]' \ -i '[x]' \ -o '[save_infer_model/scale_0.tmp_1]' \ -d 'compilation' \ --cmp
输出:
若不指定-d参数,则在当前文件夹下,默认新生成compilation文件夹存放输出的 *.fp32umodel 与 *_bmpaddle_test_fp32.prototxt。
此阶段的参数设置需要注意:
如果指定了“-D (-dataset )”参数,那么需要保证 “-D”参数下的路径正确,同时指定的数据集兼容该网络,否则会有运行错误。
若指定了“-D”参数,则按照章节 使用lmdb数据集 方法修改prototxt。
使用data layer作为输入
正确设置数据预处理
正确设置lmdb的路径
在不能提供合法的数据源时,不应该使用“-D”参数(该参数是可选项,不指定会使用随 机数据测试网络转化的正确性,可以在转化后的网络中再手动修改数据来源)。
转化模型的时候可以指定参数“--cmp”,使用该参数会比较模型转化的中间格式与原始框 架下的模型计算结果是否一致,增加了模型转化的正确性验证。
5.4. 量化,生成int8umodel¶
网络量化过程包含下面两个步骤:
量化需要用到 准备lmdb数据集 中产生的lmdb数据集,而正确使用数据集尤为重要,所以先说明如何使用数据集。
5.4.1. 使用lmdb数据集¶
对于post-training量化方法,通过将训练后的模型进行一定次数的推理,来统计每层的输入输出数据范围,从而确定量化参数。 为了使统计尽可能准确, 推理时候必须保证输入的数据为实际训练/验证时候的有效数据,前处理也保证和训练时候的一致 。
因此U-FrameWork中提供了简单的前处理接口,可通过修改产生fp32umodel时候(可参考 生成fp32umodel)生成的*_test_fp32.prototxt文件 来配置前处理算法,生成的lmdb数据在输入网络前会按照此处的配置进行计算后再进行真正的网络推理,完整的前处理可以视为制作lmdb时进行的cv转换 和prototxt中定义的前处理算法的组合。
完整定义前处理一般可以做以下三方面的修改:
使用Data layer作为网络的输入。
使Data layer的参数data_param指向生成的lmdb数据集的位置。
修改Data layer的transform_param参数以对应网络对图片的预处理。
data_layer的典型结构如下例所示:
layer { name: "data" type: "Data" top: "data" top: "label" include { phase: TEST } transform_param { transform_op { op: RESIZE resize_h: 331 resize_w: 331 } transform_op { op: STAND mean_value: 128 mean_value: 128 mean_value: 128 scale: 0.0078125 } } data_param { source: "/my_lmdb" batch_size: 0 backend: LMDB } }
特别注意,2.7.0版本开始ufwio相较于以前版本在lmdb中有新的辅助信息存储,所以格式和以前版本的lmdb有不同,制作lmdb使用python形式的接口,示例程序create_lmdb提供了可在其基础上修改的例程。推荐在python代码中将预处理一并包含,生成已经预处理过的数据供量化使用,这样就不必在prototxt中定义前处理。 制作lmdb时候需要生成与网络输入shape一致的数据,对于常见的CV类的模型数据,示例程序默认生成的lmdb是4维,当此lmdb用作转换fp32umodel命令的-D参数的输入时,上述prototxt的data layer的batch_size参数会自动设置为0,如果转换fp32umodel过程中没有指定-D参数,则手工修改prototxt指定数据源时需要注意将batch_size设置为0。 旧版SDK二进制convert_imageset工具生成的lmdb配合以前的prototxt是兼容的,它生成的lmdb为3维,如果使用新的工具创建lmdb用于以前已经转换好的fp32umodel,可能存在维度不同的现象,需要手工修改data layer的batch_size为0。旧版本的prototxt和LMDB仍然是兼容的,使用新生成的lmdb作为dataset参数转换fp32umodel也无须手工修改。
5.4.2. 修改data_param指向生成的lmdb数据集¶
1 model_type: BMNETT2UModel 2 output_whitelist: "vgg_16/fc8/squeezed" 3 inputs: "input" 4 outputs: "vgg_16/fc8/squeezed" 5 layer { 6 name: "input(data_will_be_transposed)" 7 type: "Data" 8 top: "input(data_will_be_transposed)" 10 include { 11 phase: TEST 12 } 13 transform_param { 14 transform_op { 15 op: RESIZE 16 resize_side: 256 17 } 18 transform_op { 19 op: CROP 20 crop_h: 224 21 crop_w: 224 22 } 23 transform_op { 24 op: STAND 25 mean_value: 103.94000244140625 26 mean_value: 116.77999877929688 27 mean_value: 123.68000030517578 28 scale: 1.0 29 bgr2rgb: true 30 } 31 } 32 data_param { 33 source: "/my_lmdb" // 设置为data layer的source 34 batch_size: 0 35 backend: LMDB 37 } 38 } 修改source指向正确的LMDB位置
5.4.3. 数据预处理¶
在量化网络前,需要修改网络的*_test_fp32.prototxt文件,在datalayer(或者AnnotatedData layer) 添加其数据预处理的参数,以保证送给网络的数据与网络在原始框架中训练时的预处理一致。
Calibration-tools量化工具在Caffe数据预处理表示形式基础上进行了改进。 Caffe自带的TransformationParameter参数表示方法各个参数的执行顺序相对固定, 但很难完善表达Tensorflow、Pytorch等基于Python的框架里面灵活多变的预处理方式,仅适用于Caffe模型的默认数据预处理方式。本工具改进为自定义TransformOp 数组表示方法,通过定义transform_op结构,将需要进行的预处理分解为不同的transform_op,按照顺序列在transform_param中,程序会按照顺序分别执行各 项计算,各个op的定义可以参考 TransformOp定义。
5.4.4. TransformOp定义¶
message TransformOp { enum Op { RESIZE = 0; CROP = 1; STAND = 2; NONE = 3; } optional Op op = 1 [default = NONE]; //resize parameters optional uint32 resize_side = 2 ; optional uint32 resize_h = 3 [default = 0]; optional uint32 resize_w = 4 [default = 0]; //crop parameters optional float crop_fraction = 5; optional uint32 crop_h = 6 [default = 0]; optional uint32 crop_w = 7 [default = 0]; optional float padding = 8 [default = 0];//for resize_with_crop_or_pad //mean substraction(stand) repeated float mean_value = 9; optional string mean_file = 10; repeated float scale = 11; repeated float div = 12; optional bool bgr2rgb = 13 [default = false]; }
目前支持缩放(RESIZE),剪裁(CROP)和归一化(STAND)操作。
缩放(RESIZE)参数 |
参数说明 |
|---|---|
resize_side |
图片缩放的短边的长度,图片较短的宽/高缩放到此数值,另一边按此边比例缩放,输入此参数则resize_h和resize_w被忽略 |
resize_h |
图片目标高度 |
resize_w |
图片目标宽度 |
剪裁(CROP)参数 |
参数说明 |
|---|---|
crop_fraction |
图片剪裁比例,输入图片按照此比例以中心点为参考点剪裁,如果输入此参数,则crop_h和crop_w参数被忽略 |
crop_h |
图片剪裁目标高度 |
crop_w |
图片剪裁目标宽度 |
归一化(STAND)参数 |
参数说明 |
|---|---|
mean_value |
图片均值,可以输入一个或者多个,多个情况下需要和channel数量对应。 |
mean_file |
以文件形式输入的均值 |
scale |
图片乘系数,输入数据会乘以此系数,可以输入多个,多个输入情况需要和channel数量对应。 |
div |
图片除系数,输入数据会除以此系数,可以输入多个,多个输入情况需要和channel数量对应,此参数会和scale组合计算,一般可以折算到scale中。 |
bgr2rgb |
当lmdb内的数据是bgr格式的,但是net需要输入为rgb格式时,将bgr2rgb设置为ture |
5.4.5. 量化网络¶
5.4.5.1. 运行命令¶
$ cd <release dir> $ calibration_use_pb \ quantize \ #固定参数 -model= PATH_TO/*.prototxt \ #描述网络结构的文件 -weights=PATH_TO/*.fp32umodel #网络系数文件 -iterations=200 \ #迭代次数 -winograd=false \ #可选参数 -graph_transform=false \ #可选参数 -save_test_proto=false #可选参数
这里给出了使用二进制量化工具量化网络用到的所有必要参数及部分最常用的可选参数,同时sdk中也提供了python形式的量化接口,可以参考帮助文件输入参数量化:
python3 -m ufw.cali --help -model: 量化输入网络 -weights: 量化网络的权重文件 -dump_dist: 量化过程中将统计的每层的数据分布保存在文件中,下次量化可以直接load,跳过推理统计的过程加速量化 -load_dist: 将上次量化保存的layer的数据分布加载进来跳过再次推理,提高推理速度,需要注意只能使用结构完全没有变化的网络保存的分布 -target: 量化目标运行芯片,BM1684 or BM1686 -th_method: 计算门限的算法,可以为KL(default),SYMKL,JSD,ADMM,ACIQ,MAX,PERCENTILE9999 -th_binnum: 使用KL量化算法时候可选的数据bin的个数,512-4096之间的2的幂次数值 -save_test_proto: 保存测试网络,此网络包含data layer,可用于可视化工具比较量化效果 -iterations: 量化推理次数,较多的推理次数统计的数据分布往往更准确,但是需要更多的时间 -graph_transform: 是否进行图优化 -accuracy_opt: 是否开启精度优化选项,开启后deptwise卷积会用浮点推理,默认关闭 -bitwidth: 量化后数据宽度,默认为int8: TO_INT8 -conv_group: 是否对卷积的channel进行分组,对于一些channel间数据差异大的channel按照范围排序分组,可以减少量化误差 -fold_concat_scale: 将concat和scale系数合并,将concat不同输入之间的门限差别转移到scale的系数中 -fpfwd_blocks: 将某layer开始到下一个计算layer为止的区块用浮点推理 -fpfwd_inputs: 从输入到某layer之间的layers用浮点推理 -fpfwd_outputs: 从某些layer到网络输出之间的layers用浮点推理 -merge_depwise_scale: 将depthwise的卷积和之后的scale合并,打开accuracy_opt会默认进行此操作 -merge_scale_to_conv: 将卷积之后的scale合并到卷积中 -notmerge_conv_layer: 当合并卷积和scale时候这些layer排除在外不要合并 -pad_value: 有pad的层的pad值 -per_channel: 对卷积尝试每channel量化 -random_input_compare: 优化网络时默认随机输入对比,对有些网络随机输入会造成崩溃,打开此开关用网络中data layer的源数据作为输入比较,首先需要保证网络的输入设置正确 -winograd: 是否使用winograd算法,是否真正使用需要在转bmodel时再次指定
更多网络量化相关的参 数选项参见后面 量化技巧 章节。
5.4.5.2. 命令输入输出¶
Quantization-tools进行网络量化的常用输入参数包括6部分:
quantize: 固定参数
-model= PATH_TO/*.prototxt:描述网络结构的文件,该prototxt文件的datalayer指向 准备好的数据集,如图 4.5所示
-weights=PATH_TO/*.fp32umodel:保存网络系数的文件,
这两个文件由 生成fp32umodel 章节生成。
-iteration=200:该参数描述了在定点化的时候需要统计多少张图片的信息,默认200
-winograd:可选参数,针对3x3 convolution开启winograd功能,默认值为False
-graph_transform:可选参数,开启网络图优化功能,本参数相当于在量化前先执行上面的graph_transform 命令,默认值为False
-save_test_proto:可选参数,存储测试用的prototxt文件,默认值False
Quantization-tools的输出包括5部分:
*.int8umodel: 即量化生成的int8格式的网络系数文件
*_test_fp32_unique_top.prototxt:
*_test_int8_unique_top.prototxt: 分别为fp32, int8格式的网络结构文件, 该文件包括datalayer 与原始prototxt文件的差别在于,各layer的输出blob是唯一的,不存在in-place的情况,当-save_test_proto为true时会生成这两个文件。
*_deploy_fp32_unique_top.prototxt:
*_deploy_int8_unique_top.prototxt:分别为fp32,int8格式的网络结构文件,该文件不包括datalayer
以上几个文件存放位置与通过参数“-weights=PATH_TO/*.fp32umodel”指定的文件位置相同。
量化网络参数中如果打开accuracy_opt等优化参数会在量化开始过程首先进行图优化,这个过程会进行网络推理验证优化后的网络于原网络等价, 所以会占用一定的时间,如果需要反复尝试量化,可以使用graph_transform参数单独进行网络优化,将优化后的结果作为量化的输入,不再打开quantize 量化过程中的graph_transform参数。默认配置下对输入浮点网络进行优化,包括:batchnorm与scale合并,前处理融合到网络,删除推理过程中不必要的算子等功能。 更多对浮点网络图进行优化的选项参见后面 量化技巧 章节。单独进行网络优化的命令如下:
5.4.6. 优化网络¶
5.4.6.1. 运行命令:¶
$ calibration_use_pb \ graph_transform \ #固定参数 -model= PATH_TO/*.prototxt \ #描述网络结构的文件 -weights=PATH_TO/*.fp32umodel #网络系数文件
5.4.6.2. 命令输入输出¶
Quantization-tools进行网络图优化的输入参数包括3部分:
graph_transform: 固定参数
-model= PATH_TO/*.prototxt:描述网络结构的文件,该prototxt文件的datalayer指向准备好的数据集,如 data_source_set 所示。
-weights=PATH_TO/*.fp32umodel:保存网络系数的文件。
这两个文件由 生成fp32umodel 章节生成。
Quantization-tools进行网络图优化的输出包括2部分:
PATH_TO/*.prototxt_optimized
PATH_TO/*.fp32umodel_optimized
为了和原始网络模型做区分,新生成的网络模型存储的时候以“optimized”为后缀。以上两 个文件存放在与通过参数“-weights=PATH_TO/*.fp32umodel”指定的文件相同的路径下。
5.4.7. 级联网络量化¶
级联网络的量化需要对每个网络分别进行量化,对每个网络分别准备LMDB和量化调优。
5.5. 精度测试(optional)¶
精度测试是一个可选的操作步骤,用以验证经过int8量化后,网络的精度情况。该步骤可以安排在 部署 描述的网络部署之前, 并配合 量化网络 反复进行,以达到预期的精度。精度测试往往也利用部署后的测试环境测试,根据实际精度结果进行量化效果的评估。
根据不同的网络类型,精度测试可能是不同的,精度测试常常意味着要进行完整的前处理和后处理以及精度计算程序开发。Calibration-tools 对外提供了U-FrameWork的应用接口,可以对umodel进行float32或者int8推理,从而计算网络推理精度。
对于传统的分类网络和检测网络,Calibration-tools提供了两个示例,以演示如何进行精度验证。
5.5.1. 分类网络的精度测试¶
章节 示例1:classify_demo 作为示例程序,描述了分类网络精度测试的方法。
测试原始float32网络的精度
$ cd <release dir> $ ufw test_fp32 \ #固定参数 -model=PATH_TO/\*_test_fp32_unique_top.prototxt \ #章节量化网络中 输出的文件 -weights= PATH_TO/\*.fp32umodel \ #fp32格式的umodel -iterations=200 #测试的图片个数
测试转换后的int8网络的精度
$ cd <release dir> $ ufw test_int8 \ #固定参数 -model=PATH_TO/\*test_int8_unique_top.prototxt \ #章节量化网络中输出的文件 -weights= PATH_TO/\*.int8umodel \ #章节量化网络中输出的文件,量化后int8umodel -iterations=200 #测试的图片个数
5.5.2. 检测网络的精度测试¶
本工具提供接口函数供外部程序调用,以方便精度测试程序搜集到网络推理结果,进而得到 最后的精度。本工具提供python接口供用户调用。完整的python接口,见章节附录 U-FrameWork python接口。
章节 示例3:face_demo 作为示例程序,描述了C接口的调用方法。 本节是对章节 示例3:face_demo 的抽象总结。
一个c接口的精度测试程序的框架如图 c接口形式精度测试框架
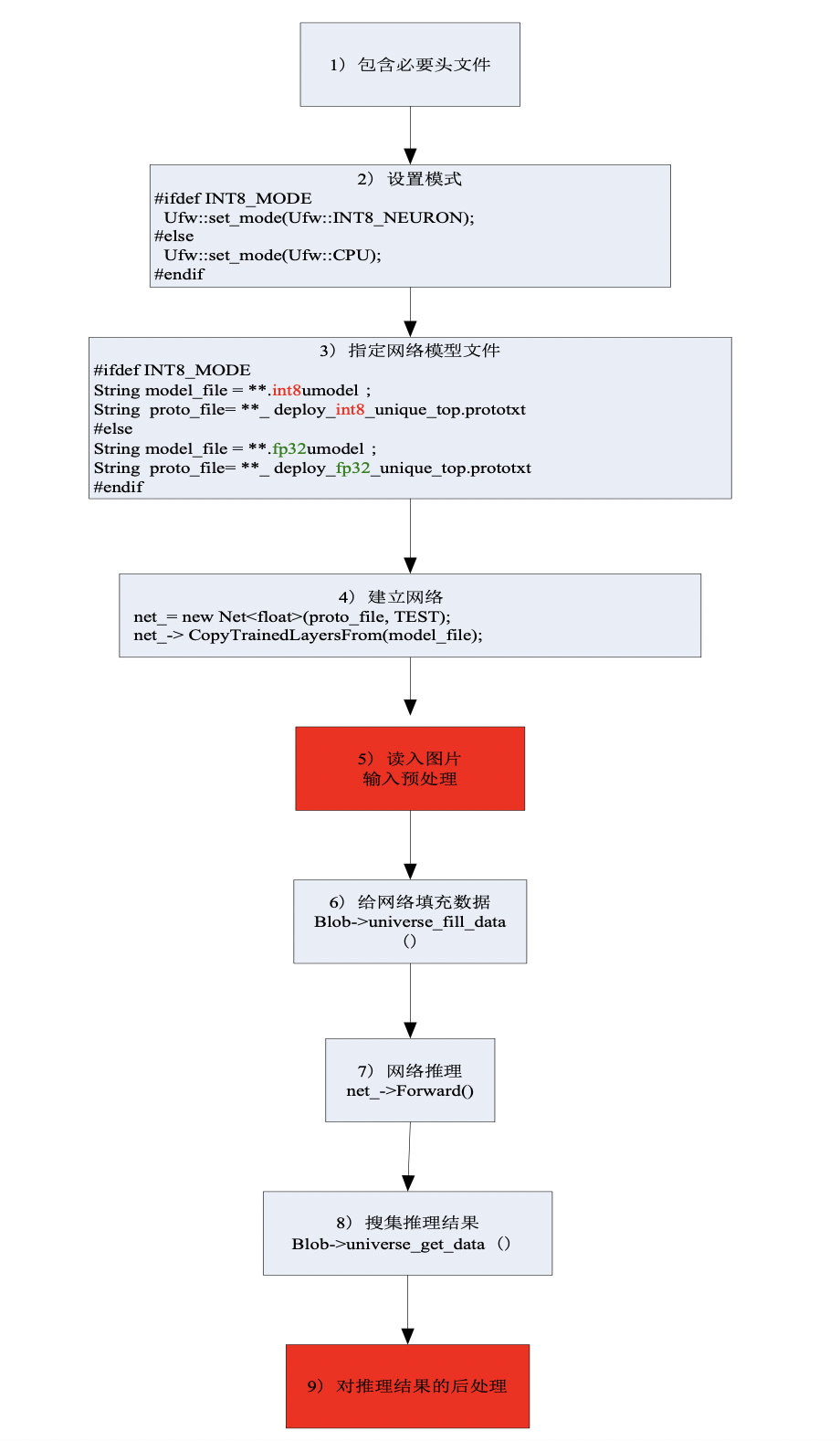
图 5.1 c接口形式精度测试框架¶
包含必要头文件
#include <ufw/ufw.hpp> using namespace ufw;
设置模式
#ifdef INT8_MODE Ufw::set_mode(Ufw::INT8); //运行int8网络的时候,设置为Ufw::INT8 #else Ufw::set_mode(Ufw::FP32); //运行fp32网络的时候,设置为Ufw::FP32 #endif
指定网络模型文件
运行fp32网络时候,用
String model_file = "**.fp32umodel"; String proto_file= "**_deploy_fp32_unique_top.prototxt";
运行int8网络时候,用
String model_file = "**.int8umodel"; String proto_file= "**_deploy_int8_unique_top.prototxt";
建立网络
net_= new Net<float>(proto_file, model_file, TEST); //proto_file描述网络结构的文件 //model_file描述网络系数的文件
读入图片,预处理
该步骤与待测的检测网络本身特性有关。采用原始网络的处理代码即可。
给网络填充数据
将经过预处理的图片数据填充给网络:
//根据输入blob的名字(这里是“data”),得到该blob的指针 Blob<float> *input_blob = (net_-> blob_by_name("data")).get(); //根据输入图片的信息,对输入blob进行reshape input_blob->Reshape(net_b, net_c, net_h, net_w); //resized的类型为cv::Mat;其中存储了经过了预处理的数据信息 // universe_fill_data()函数会将resized中的数据填充给网络的输入blob(这里是input_blob) input_blob->universe_fill_data(resized);
网络推理
net_->Forward();
搜集网络推理结果
通过这种方法得到的是网络输出数据的指针,例如const float* m3_scores
//根据输出blob的名字(这里是m3@ssh_cls_prob_reshape_output),net_->blob_by_name得到该blob的指针 Blob<float>* m3_cls_tensor = net_->blob_by_name("m3@ssh_cls_prob_reshape_output").get(); // universe_get_data()函数返回float *类型的指针,该指针指向该blob内的数据 const float* m3_scores = m3_cls_tensor->universe_get_data();
网络输出blob的名字,可以通过查看**_ deploy_fp32_unique_top.prototxt文件得到
对推理结果的后处理
该步骤与待测的检测网络本身特性有关。采用原始网络的处理代码即可。
章节 示例4:object_detection_python_demo 作为示例程序,描述了python接口的调用方法。 本节是对章节 示例4:object_detection_python_demo 抽象总结。
一个python接口的精度测试程序的框架如图 python接口形式精度测试框架
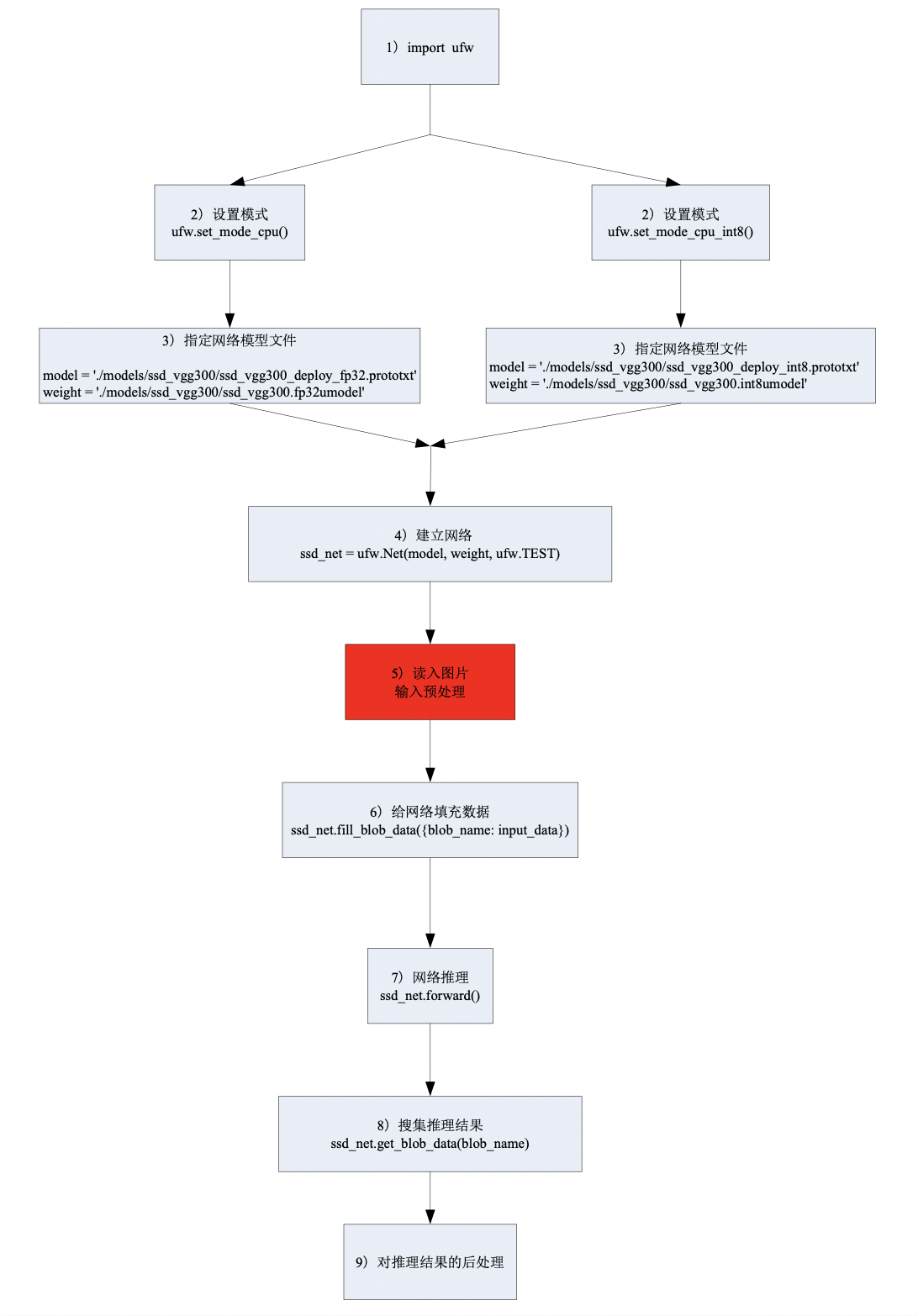
图 5.2 python接口形式精度测试框架¶
载入ufw
import ufw
设置模式
fp32模式时:
ufw.set_mode_cpu()
int8模式时:
ufw.set_mode_cpu_int8()
指定网络模型文件
运行fp32网络时候,用
model = './models/ssd_vgg300/ssd_vgg300_deploy_fp32.prototxt' weight = './models/ssd_vgg300/ssd_vgg300.fp32umodel'
运行int8网络时候,用
model = './models/ssd_vgg300/ssd_vgg300_deploy_int8.prototxt' weight = './models/ssd_vgg300/ssd_vgg300.int8umodel'
建立网络
ssd_net = ufw.Net(model, weight, ufw.TEST)
读入图片,预处理
该步骤与待测的检测网络本身特性有关。采用原始网络的处理代码即可
给网络填充数据
将经过预处理的图片数据填充给网络
ssd_net.fill_blob_data({blob_name: input_data})
网络推理
ssd_net.forward()
搜集网络推理结果
ssd_net.get_blob_data(blob_name)
对推理结果的后处理
该步骤与待测的检测网络本身特性有关。采用原始网络的处理代码即可。
5.5.3. 量化误差定性分析¶
章节 view-demo 作为示例程序,描述了如何使用calibration可视化分析工具查看网络量化误差,此工具通过运行fp32和int8网络, 并对其每层的输出进行比较,以图形化界面形式直观显示每层数据的量化损失。
该工具使用MAPE(Mean Abusolute Percentage Error)和COS (Cosine Similarity)作为误差评价标准,其计算定义为:
\[\text{MAPE} = \frac{1}{n}\left( \sum_{i=1}^n \frac{|Actual_i - Forecast_i|}{|Actual_i|} \right)\]\[\text{COS} = \frac{\sum_{i=1}^n{a_i*b_i}}{\lVert A \rVert_2 \cdot \lVert B \rVert_2 + \text{eps}}\]\[\text{DIST} = \frac{1}{1 + \sqrt{ \sum_{i=1}^n (a_i - b_i)^2}}\]
由于int8网络部分层进行了合并计算,例如会将relu与batchnorm合并,所以此时bathcnorm 层的评价参数值无效。
此量化工具以Web App形式提供,由于量化工具在Docker中运行,使用此量化工具时候可能需要在Docker启动脚本中增加端口 映射选项,如 Docker端口映射启动 所示,在SDK的启动脚本docker_run_bmnnsdk.sh中增加端口映射选项-p,Docker内端口8000被 映射为主机端口8000。根据启动Docker时的配置,使用ufw.tools.app时,其“–port” 参数需要与Docker内端口映射匹配。
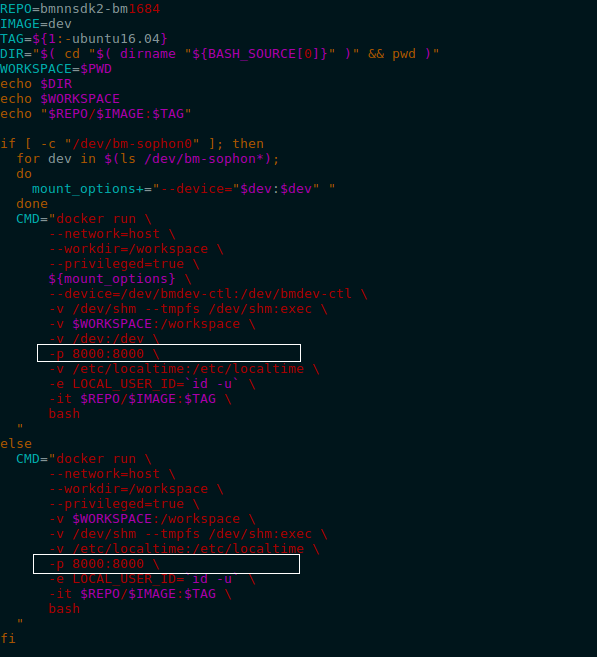
图 5.3 Docker端口映射启动¶
SDK中附带了演示可视化工具的示例,保存在examples/calibration/view_demo, 该用例程序以resnet18为例,描述如何分析量化后int8模型与原始float模型的精度差异。
在Docker的SDK环境中运行命令:
$ cd <release dir>/examples/calibration/view_demo $ python3 -m ufw.tools.app --port 8080 # default port:8050
运行结果如 可视化分析工具 所示。
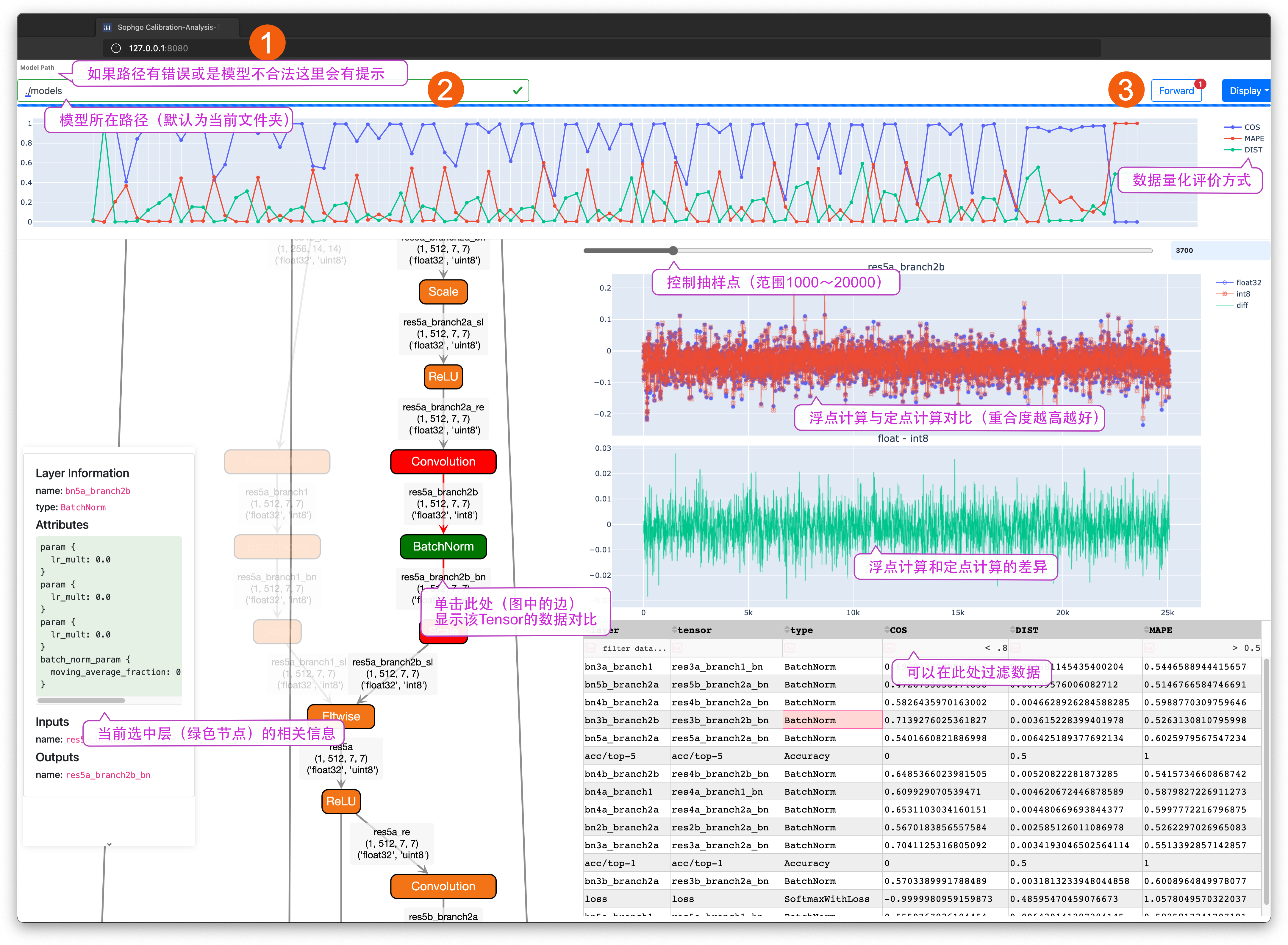
图 5.4 可视化分析工具¶
根据建立docker时设置的端口号(这里以8080为例),在浏览器中输入localhost:8080(对 应图中位置1),即 可进入可视化分析工具界面。在模型路径(对应图中位置2)中输入 “./models/”然后回车,就可以在Graph显示区域中看到网络结构图。使用“Forward”按钮 (对应图中3)对网络执行前向推理,完成后可以看到Graph上的信息得到更行,包括: Tensor的shape,该网络在浮点和定点模式下对应Tensor的计算方式。相关说明见图 可视化分析工具 中的标注。

图 5.5 量化评价参数¶
在评价参数区域中点选相应的数据,此时Graph和数据对比区域会同步更新。
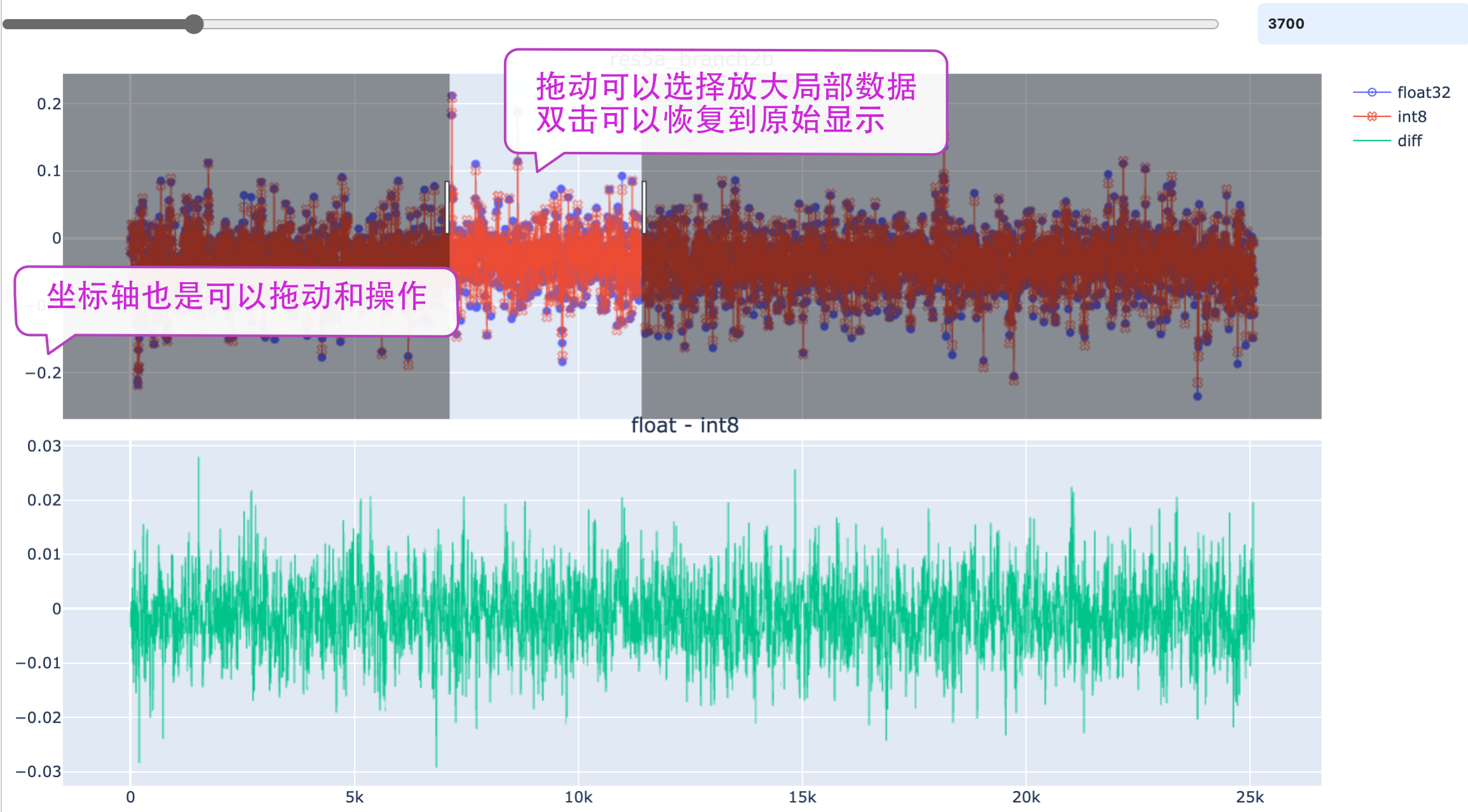
图 5.6 数据对比图¶
在 数据对比图 中使用滑动条控制抽值采样的点数。增加采样点会让数据显示的更加 丰富和真实,但是较多的采样点会影响app的响应速度。相关的操作见图中的提示。
Display菜单可以控制app中的元素显示方式,如控制Graph的Layout效果,隐藏悬浮窗口。 抓取悬浮窗口的顶端可以把它拖动到其他位置。数据过滤器支持“>”,“<”,“=”,“!=”运算方式。
5.6. 部署¶
部署指的是用int8umodel,生成SOPHON系列AI平台指令集。网络部署时,涉及到以下两个文 件:
**.int8umodel, **_deploy_int8_unique_top.prototxt
以上两个文件会送给bmnetu,最终生成可在SOPHON系列AI运算平台上运行的bmodel,具体步骤请参考文档NNToolChain.pdf中bmnetu相关的部分及BmnnSDK下的相关example。