5. 模型转换及量化常见问题¶
开发文档:《 NNToolChain用户开发手册 》、《 量化工具用户开发手册 》
5.1. 基本使用¶
5.1.1. pytorch模型转换需要注意的事项?¶
什么是JIT(torch.jit)?
答:JIT(Just-In-Time)是一组编译工具,用于弥合PyTorch研究与生产之间的差距。它允许创建可以在不依赖Python解释器的情况下运行的模型,并且可以更积极地进行优化。
支持什么格式的pytorch模型?
答:Sophon的PyTorch模型编译工具BMNETP只接受PyTorch的JIT模型JIT模型(TorchScript模型)。
如何得到JIT模型?
答:在已有PyTorch的Python模型(基类为torch.nn.Module)的情况下,通过torch.jit.trace得到;traced_model=torch.jit.trace(python_model, torch.rand(input_shape)),然后再用traced_model.save(‘jit.pt’)保存下来。
为什么不能使用torch.jit.script得到JIT模型?
答:BMNETP暂时不支持带有控制流操作(如if语句或循环)的JIT模型,但torch.jit.script可以产生这类模型,而torch.jit.trace却不可以,仅跟踪和记录张量上的操作,不会记录任何控制流操作。
为什么不能是GPU模型?
答:BMNETP的编译过程不支持。
如何将GPU模型转成CPU模型?
答:在加载PyTorch的Python模型时,使用map_location参数:torch.load(python_model, map_location = ‘cpu’)。
5.1.2. 模型转换失败怎么办?¶
答:
检查命令行输入参数有没有错误,这个一般会有打印提示;
不支持的算子需要使用BMLang或者OKKernel开发,也可以联系FAE来解决;
如果是pytorch模型,是不是没有做trace?
使用转换工具编译模型时,设置环境变量export BMCOMPILER_STAT_ERR=1,然后加上–v 4,保存更详细的日志,提供给我方技术人员进一步排查;
有时转换失败是因为误差比对超过了允许的阈值而导致编译过程中断,目前比对误差阈值设置为误差在0.01之内,但也不排除有些模型有很多的累加或除法操作,由于尾差累计导致超出这个范围;可以加上–cmp False关闭比对,最终到业务层面上验证转换后的模型精度是否符合要求;
2.7.0以后的sdk可以通过BMCOMPILER_STAT_ERR=1,来看每层的数据相似度,个别超过误差不会中断完整编译过程。
5.1.3. 如何使用BMLang开发自定义的算子?¶
BMLang是算能科技面向用户推出的针对BM168x TPU的一套高级编程接口库,使得用户可以快速的基于TPU硬件开发自定义算子,甚至整个神经网络。BMLang的基本元素是:张量数据(bmlang::Tensor)和计算操作(bmlang::Operator)。用户需要使用bmlang::Tensor和bmlang::Operation来编写C++代码,然后在程序最后使用bmlang::compile或bmlang::compile_with_check来生成TPU可以运行的二进制文件bmodel,与普通网络编译产生的BMODEL文件一样,依赖于BMRuntime接口载入与执行。
5.1.4. 是否支持模型的在线编译?¶
答:不支持,也不推荐这样做,因为模型编译的过程是特别耗时的。因此我们采用了离线编译生成BModel,在线推理时直接加载BModel运行的方式。
5.2. fp32模型转换¶
5.2.1. fp32模型的输出和原始模型输出差异比较大怎么办?¶
答:
对于两个模型采用同样的输入,看看输出是否一致,比如输入都是用全部是0.1的矩阵,填充input tensor的内存空间,然后做推理,比较输出数据的差异;
设置 export BMRT_SAVE_IO_TENSORS=1,运行bmruntime的时候会输出两个文件 input_ref_data.dat.bmrt和output_ref_data.dat.bmrt,用这个和理想的输入输出作对比排查;比较数据时尽量使用二进制比较,不要通过打印的数据比较,因为打印的输入格式不一样,也会导致数据显示不一样。
5.2.2. 使用bmpaddle转换模型时应该如何填写参数?descs 参数是选填还是必填?¶
答:示例:
python3 -m bmpaddle --model=model/ --input_names="image,im_size" --shapes="[1, 3, 608, 608],[1, 2]" --target="BM1684" --cmp=true --
descs="[1,int32,608,609]"
注意
–model参数到模型所在文件夹那一级;paddle模型有2种:组合式(combined model)和非复合式(uncombined model);组合式就是__model__ + 权重,__model__文件夹下有很多文件,每一个文件是一层,这种模型名称必须用__model__;如果是非组合式,要用.pdmodel和.pdiparams;
shapes和descs中的变量顺序、名称要和实际模型一致,不能写错;
关于descs 参数是选填还是必填?对于模型中带nms的目标检测网络,并且cmp==true时descs必填,并且对于多输入时的其他输入(比如paddle检测模型中通常都会有的im_size参数),必须写明。对于没有填的输入,默认会产生0-1的随机数,比如输入图像,可以不填;当类型为int32时,不能填重复的值,故写608,609,但生效的就是608;float类型没这个限制;
paddle-ocr-detection开比对会有误差累计,报错。另外有的模型算子中有很多累加或除法,由于误差累计会导致超出允许的比对误差阈值,转换中断报错;还有的有排序操作,小误差会导致顺序不同。这些都会导致转换中断,可以关闭cmp,不进行数据比对,到业务层面验证转换后模型的精度。
5.3. int8模型量化¶
5.3.1. int8的输出和fp32模型输出差异比较大怎么办?¶
答:
检查前后处理是否有问题,int8网络输入输出一般需要做scale处理,看看是否遗漏?
通过量化可视化工具分析int8的输出和fp32的输出的精度差异,做个输出曲线对比;通过曲线查找出导致误差较大的层,通过更换该层的量化方式调整结果,找到最优量化方式,若仍然不能满足精度要求,则可将该层设置为float输出,不进行量化。
5.3.2. 关于模型量化工具 calibration_use_pb 指定校准参数的问题?¶
calibration_use_pb 这个工具和校准相关的参数:
问:
这三个参数是互斥的存在,还是可以组合使用?
per_channel 这个参数指定成 true 之后,还需要其他的参数配合吗? 比如: first_conv_enable_per_channel
th_method 这个参数可以同时指定多个吗? 比如同时指定:-th_method=SYMKL, -th_method=JSD
答:accuracy_opt针对depthwise的卷积,如果没有depthwise可以不选,跟th_method不冲突,th_method一次只能选一种,per_channel可以单独使用。
5.3.3. 如何提高模型的量化效率和精度?¶
答:推荐策略是:
对于检测和分类模型,使用自动量化工具,量化成功后精度测试;
对于其他类模型,手动指定量化参数,量化成功后精度测试;
自动量化失败 或 精度不够的,反馈给我们的技术支持。
5.3.4. 关于量化方法的问题?¶
问:手动指定量化参数时,需要尝试18种量化方法的组合,并逐个测试精度。是否可以提供相关量化参数的说明及推荐使用方法?我们希望能根据模型结构缩小量化方法的搜索范围。
答:kl和symkl和jsd算法比较相似可能差别不大,bert一般用max。多数网络max表现一般,但是各种算法和网络结构和用户训练结果都有关系,所以先默认kl量化,下降多的话再尝试其他组合可能省些时间。
问:这些量化方法 对量化后模型的性能有影响吗?
答:几种门限算法对性能没影响,accuracyopt会把depthwise卷积用浮点,一般会变慢,perchannel也会变慢,这两个是为了提高精度。
5.3.5. 可以使用已有的量化表(比如 TensorRT 量化后得到的量化表)作为输入 来完成BModel模型的量化吗?¶
答:目前不支持,主要是我们前端转换成umodel之后网络的layer的名字都对不上了。
5.3.6. YOLOv3的darknet模型先转为caffe模型后再转为fp32bmodel,模型输出和原始模型输出存在偏差?¶
答:darknet模型转caffe模型过程中可能存在偏差,建议直接用darknet模型转为fp32bmodel。将YOLOv3的darknet模型直接转为bmodel,推理结果没有偏差。
5.3.7. 使用bmnetd编译Darknet出现段错误Unknown error 27620053?¶
答:编译模型段错误时,检查xxx.cfg文件,如果在windows系统下保存或修改过,由于和linux系统对换行符表示不同,会导致解析出错引起段错误,可以用命令转换:
dos2unix xxx.cfg
5.3.8. 使用BMNNSDK2.7.0_20220316 auto_calib工具时报错base_conv_layer.cpp43] Check failed: num_spatial_axes_ == 2 (3 vs. 2) kernel_h & kernel_w can only be used for 2D convolution¶
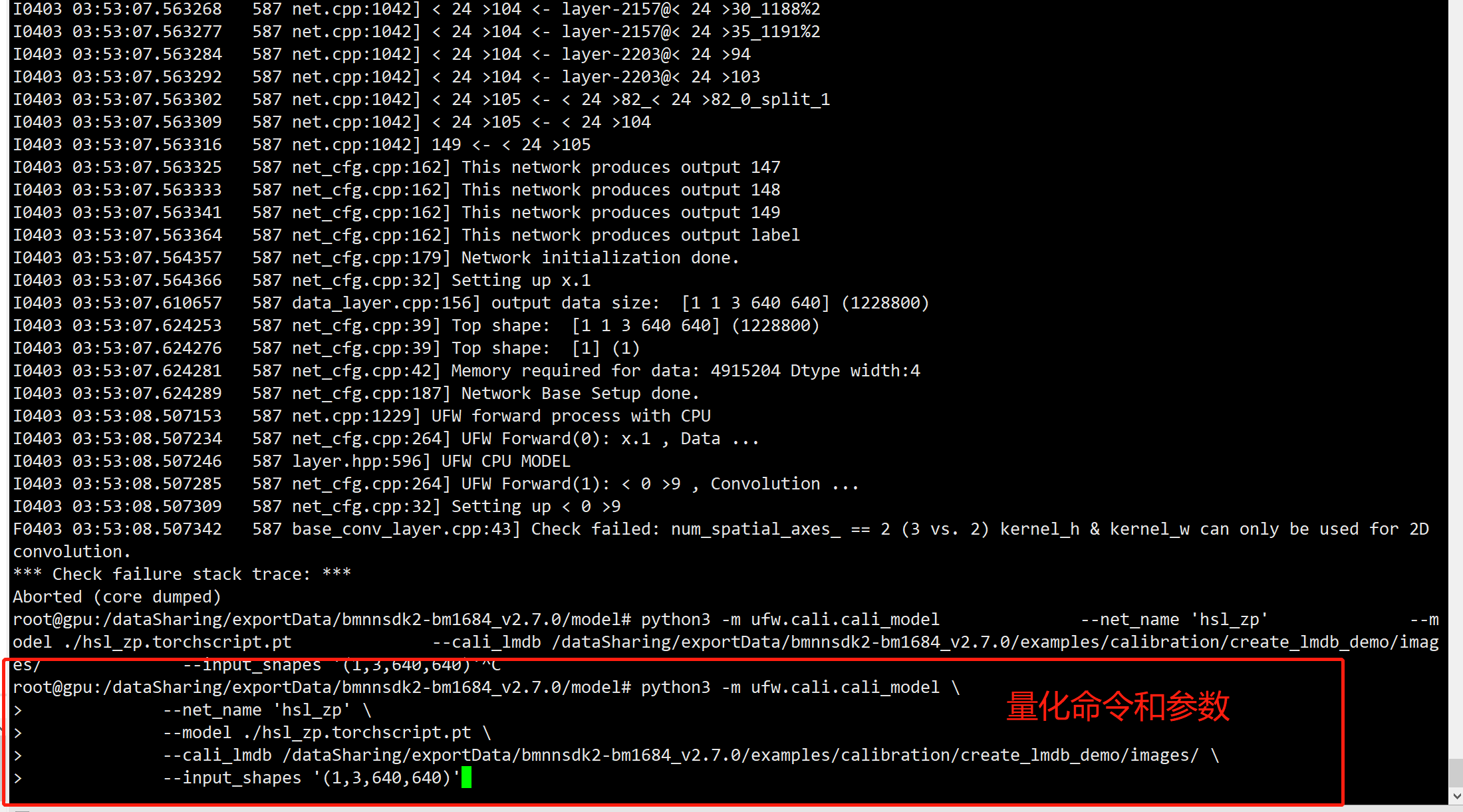
答:关于使用SDK 2.7.0_20220316自动量化工具时报错的问题:
使用auto_calib ufw.calib.cali_model 为了兼容之前就版本SDK生成的LMDB文件,要求LMDB必须是 3, 640, 640这种的,而不能是 1 3 640 640
删除examples/calibration/create_lmdb/convert_imageset.py中 cv_img = np.expand_dims(cv_img,axis=0) 这一句,重新生成lmdb。 新生成lmdb时,请先删除掉原先生成的lmdb那个文件夹,否则无法覆盖原先生成的。刚才您应该是已经有之前生成的文件了,所以修改后没生效。
如果 auto_calib ufw.calib.cali_model的preprocess参数可以满足模型预处理要求,那么使用时可以直接使用图片集,这个不会涉及LMDB文件数据的维度。
补充说明:使用手动分步方式量化模型时,也要注意,如果使用的是 1 3 640 640 这样的lmdb,那么修改使用ufw.tools.xx_to_umodel 生成的fp32umodel prototxt时,prototxt里要batch_size要设置为 0 (如果在使用ufw.tools.xx_to_umodel时,指定了-D=”${lmdb_dst_dir} 那么程序自动会在生成的protoxt里将batch size设置为0);如果使用的是3 640 640 这样的lmdb,那么fp32umodel prototxt里batch_size要设置为 1。 具体说明,请参考https://doc.sophgo.com/docs/docs_latest_release/calibration-tools/html/module/chapter4.html#using-lmdb
5.3.9. 一键量化会不会遍历KL、MAX这些量化策略,策略的细节有哪些?¶
答:autocalib会遍历所有量化策略,循环进行量化和测试精度的过程,叠加每次进行多次 iteration 的推理,选优提高量化精度。目前搜索策略有:

5.3.10. 量化策略里的MAX方法是指min-max吗?¶
答:MAX是用最大值作为量化阈值,不是min-max。