编译优化器插件¶
编译与使用¶
优化器plugin文件夹在$(BMNNSDK)/bmnet/bmcompiler下,其结构如下图所示:
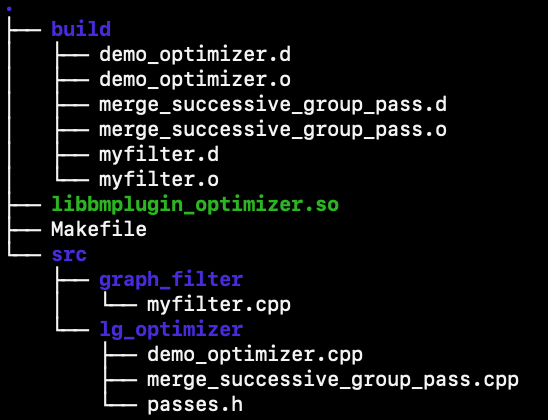
其中,src是plugin的源码目录,主要存放plugin的源码; build文件夹是在编译时自动生成的,存放目标文件; libbmplugin_optimizer.so是生成的插件文件。 src中,graph_filter是自定义图优化开发目录,lg_optimizer是Layer Group后端优化器自定义开发目录。
编译步骤¶
编译依赖于需要libbmcompiler.so及其对应的include文件夹。
在plugin目录下运行make命令,即可在当前目录下生成libbmplugin_optimizer.so文件
使用方法¶
在编译网络时,bmcompiler会在当前目录下查找*.so文件,试图通过查找统一接口来注册的功能;
设置BMCOMPILER_PLUGIN_PATH环境变量,来指定plugin的目录或.so文件, 可以指定多个,用”:”分隔;
对于指定的目录,bmcompiler会优先从环境变量设置的路径查找*.so文件,最后加载当前目录文件*.so文件;
对于指定的.so文件,bmcompiler直接加载当前目录文件*.so文件;
调用bmcompiler_if.h中定义的load_plugin接口,加载指定位置的plugin
自定义图优化filter¶
bmcompiler内部图的表示¶
bmcompiler内部图的表示是通过Graph类, GraphNode类, GraphEdge类定义的,头文件是”bmcompiler_basics.h”
GraphNode类对应于Layer的概念,记录了当前的层的类型,及对应的参数,以及其与输入输出Tensors关系。重要的成员有: - id: 唯一标识,通常按照加层的顺序递增 - name: 层名称 - ins: 输入Tensor的vector - outs: 输出Tensor的vector - param: 该层的具体参数
GraphEdge对应于Tensor的概念,具有类型、数据类型、Shape等属性,并记录与来源及输出Layer之前的关系 - id: 唯一标识,通常按照加层的顺序递增 - name: 进行数据比对时,会根据名字查找参考数据 - in: 输出该Tensor的Layer - outs: 输出Layer的vector - param: 该Tensor的具体参数
Graph包含了整个图的全局信息, 如输出信息、动态标记等,同时还包含一些图操作,如add_layer, add_tensor等,主要成员和方法如下
add_layer(layer_param, ins={}, outs={})
add_tensor(tensor_param)
delete_layer_with_ins(layer)
delete_layer_with_outs(layer)
delete_layer_with_inout(layer)
foreach_layer(visit_func, is_reverse=false)
foreach_tensor(visit_func, is_reverse=false)
下图为图的连接示意:
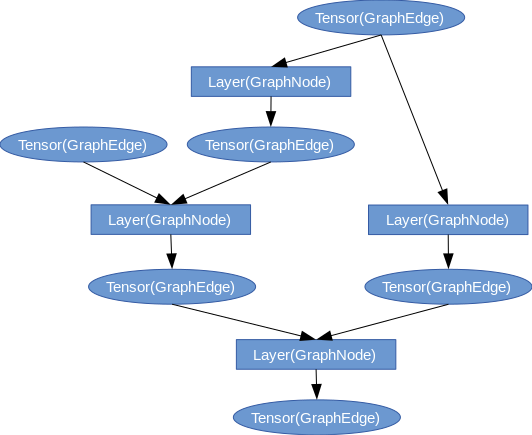
bmcompiler图基本操作¶
由于layer和tensor内部有ins/in及outs双向连接关系,可以从一个tensor或一个layer来遍历整张图
layer增加一个input时, 要把layer与tensor,及tensor与layer连接上
layer->ins.push_back(tensor);
tensor->outs.push_back(layer);
layer增加一个output时, 要把layer与tensor,及tensor与layer连接上
layer->outs.push_back(tensor);
tensor->in = layer
注意事项:
要保证layer和tensor,及tensor和layer之间的连接关系;
tensor的outs顺序可以随意,但最好保持唯一性;
layer的ins和outs中的tensor顺序是有意义的
图操作后,要注意整张图的最终输入和输出的tensor名称是否和原图一致,否则会在实际部署中引起输出名称变化
对特定layer优化后,考虑输出tensor的数据是否和原来一致,如果实在无法做到,可以用graph->set_tensor_compare_ignored(tensor)取消对该tensor检查
filter的运行流程¶

说明:
步骤1和8的callbacks是在逐层处理前,对整图进行处理,如打印,导出等操作
filter根据优先级分组,按照值从小到大排列,即优先级值小,表示优先级越高。
如果当前优先级不会导致图发生变化,就进行下一优先级处理,否则 从头开始
LAYER_FIRST和LAYER_LAST是特殊的层类型,在每一层对应类型的filter应用前后,都会分别调用这两层对应的filter
filter的编写¶
filter的通用接口¶
bool my_filter(Graph* graph, GraphNode* layer); // 对应流程步骤5,6,7步的layer filter接口
bool my_callback(Graph* graph); // 对应流程步骤1和8的callbacks
filter的优先级¶
目前在bmcompiler_filter中预定义了以下优先级的filters,内部使用了 FILTER_PRIORITY_TPU0 、 FILTER_PRIORITY_TPU1 、 FILTER_PRIORITY_CPU 三种
用户可根据自定义filter对图的影响来设置优先级, 优先级值越低,表示越先执行。比如可采用 FILTER_PRIORITY_TPU0+1 表示在 FILTER_PRIORITY_TPU0 完成后再执行
#define FILTER_PRIORITY_PRE 100
#define FILTER_PRIORITY_TPU0 200
#define FILTER_PRIORITY_TPU1 300
#define FILTER_PRIORITY_CPU 400
#define FILTER_PRIORITY_POST 500
filter通过plugin注册¶
filter注册块在filter中只允许出现一处,否则会报重复定义错误。 在bmcompiler_filter.h中定义了注册辅助宏,使用示例如下
BM_FILTERS_BEGIN() // 标记开始定义filters, 注意后面没有分号
// BM_FILTER定义需要依次提供四个基本信息: 优先级、层类型、filter函数、filter功能说明
BM_FILTER(FILTER_PRIORITY_TPU0, BMNET_ACTIVE, filter_inverse_active,"remove inversed active layers"),
BM_FILTERS_END() // 标记结束定义filters, 注意后面没有分号
// callback定义是可选的, 如无需要,可以不定义
BM_FILTER_PRE_CALLBACKS_BEGIN() // 标记callback开始, 注意后面没有分号
BM_FILTER_CALLBACK(pre_callback), //提供callback函数
BM_FILTER_PRE_CALLBACKS_END() // 标记callback结束, 注意后面没有分号
BM_FILTER_POST_CALLBACKS_BEGIN() // 标记callback开始, 注意后面没有分号
BM_FILTER_CALLBACK(pre_callback), //提供callback函数
BM_FILTER_POST_CALLBACKS_END() // 标记callback结束, 注意后面没有分号
自定义后端优化器PASS¶
Sohpon TPU的后端编译优化器是基于Layer group的优化体系,所以所有的后端优化PASS都需要在Layer group的基础上添加。关于Layer group的优化体系如用户有兴趣可联系我们进行深入交流。
自定义优化器¶
自定义优化器用于管理用户自定义的优化PASS。每位用户可以定义自己的优化器, 并注册进Sophon编译器中。优化器可以定义一个,也可以定义多个,但一般建议一个用户团队 只定义一个优化器来管理自己的所有自定义优化PASS。
下面是一个自定义优化器的Demo。
#include "bmcompiler_core.h"
#include "lg_optimizer/passes.h"
namespace bmcompiler {
class DemoOptimizer : public LgOptimizer {
public:
virtual void manage_passes(std::shared_ptr<LgPassManager> pm,
const LgOptions& options) override {
// Add a demo pass
pm->add_pass(CreateMergeTwoSuccessiveGroupPass());
}
virtual std::string brief() override { return "This is the demo of plugin optimizer."; }
};
REGISTER_LG_OPTIMIZER(SophonDemo, DemoOptimizer);
}
新定义的class DemoOptimizer是一个自定义优化器,它必须继承于基类LgOptimizer。用户在定义自己的优化器时可以给该class取任意名字。 优化器类中主要有两个成员函数,分别是manage_passes和brief。
成员函数brief是用一句话来简短描述自定义优化器,例如A用户自定义优化器的brief可以是“This is A’s optimizer.”。
成员函数manage_passes则是管理用户自定义PASS的主函数。它有两个参数,一个是PASS管理器pm,用于装载pass;另一个参数是options,是用户在管理自定义PASS时的参考选项。 管理PASS的过程则是根据options调用pm->add_pass()来向pm增加用户自定义优化PASS的过程。 pm里的PASS在执行时根据其add的先后顺序来进行。
最后则是调用REGISTER_LG_OPTIMIZER将自己的优化器注册到Sophon编译器中。 如上面代码显示,注册时需要给两个参数。一个参数是名字,名字是可以任意取的,但必须要能做到名字唯一性,否则后注册的优化器会覆盖掉前面注册的名字相同的优化器。 另一个参数是用户自定义的优化器class。这里SophonDemo是注册的DemoOptimizer的名字。
下面是LgOptimizer、LgPassManager和LgOptions的定义。
struct LgOptions {
bool dyn_compile;
};
/// Pass manager of layer group optimization
class LgPassManager {
public:
LgPassManager() {}
~LgPassManager() {}
void add_pass(std::unique_ptr<LgPass> pass);
void run(LgPassIR* pass_ir, Context* ctx);
private:
std::vector<std::unique_ptr<LgPass>> passes;
};
/// Layer group optimizer
class LgOptimizer {
public:
LgOptimizer() {}
virtual ~LgOptimizer() {}
virtual void manage_passes(std::shared_ptr<LgPassManager> pm,
const LgOptions& options) = 0;
virtual std::string brief() = 0;
};
目前LgOptions只有一个成员变量dyn_compile,true表示正在使用动态编译,false则表示正在使用静态编译。
LgPassManager的passes用于装载优化PASS。其成员函数有add_pass和run。add_pass如之前所介绍。 成员函数run会按顺序执行passes中的所有PASS,run会在Sophon编译器内部调用,一般不建议用户来调用。
LgOptimizer的成员函数如之前的DemoOptimizer所介绍。
添加自定义优化PASS¶
这里介绍如何增加一个用户自定义的后端优化PASS。添加一个后端优化PASS有三个步骤:
基于基类LgPass创建一个优化PASS派生类
基类LgPass如下所示。这个类主要有三个成员函数:run、name和brief。
成员函数run是该优化PASS的执行,他有两个参数,一个参数是pass_ir,一个参数是ctx。 pass_ir是我们要操作的基于Layer group优化体系的中间表示(IR),有关pass_ir的详细信息将在下面介绍。 ctx则是Sophon编译器的context,context不需要用户操作。
成员函数name用于返回该PASS的名字。
成员函数brief用于返回该PASS的一句简短介绍。
/// Pass of layer group optimization
class LgPass {
public:
LgPass() {}
virtual ~LgPass() {}
virtual bool run(LgPassIR* pass_ir, Context* ctx) = 0;
virtual std::string name() = 0;
virtual std::string brief() { return ""; }
};
Demo中提供了一个优化PASS,叫MergeTwoSuccessiveGroupPass,如下所示。其中成员函数run中调用了 merge_two_successive_group,这个函数是该PASS的具体实现。成员函数run在成功时需要返回true, 表示该PASS执行成功,失败则返回false。
class MergeTwoSuccessiveGroupPass : public LgPass {
public:
virtual bool run(LgPassIR* pass_ir, Context* ctx) override {
merge_two_successive_group(pass_ir->graph_, pass_ir->layer_groups_,
pass_ir->time_steps_, pass_ir->shape_secs_,
pass_ir->subnet_layers_, ctx);
return true;
}
virtual std::string name() override { return "MergeTwoSuccessiveGroupPass"; }
virtual std::string brief() override {
return "Show how to write a layer group optimizer pass";
}
};
编写PASS创建函数
完成LgPass的派生类编写后,然后我们需要编写PASS创建函数。其格式如下所示, 这是一个PASS创建函数Demo。
std::unique_ptr<LgPass> CreateMergeTwoSuccessiveGroupPass() {
return std::unique_ptr<LgPass>(new MergeTwoSuccessiveGroupPass());
}
之前的自定义Demo优化器在管理PASS时,通过add_pass添加的是该PASS创建函数。如自定义Demo优化器的代码所示。
优化PASS的具体实现
接下来我们需要完成优化PASS的具体实现。Demo中的merge_two_successive_group是在尝试将相邻两个Layer group合成一个Layer group。具体实现可以参考Demo代码。
LgPassIR介绍¶
LgPassIR信息如下所示。
struct LgPassIR {
LgPassIR();
~LgPassIR();
/**
* Clear information of layer group IR
*/
void clear();
/**
* @brief the whole graph
*/
Graph* graph_;
/**
* @brief the layers in the current subnet graph
*/
std::vector<LayerId> subnet_layers_;
/**
* @brief the layer groups.
* layer_groups.size() means the number of groups.
* layer_groups[i].size() means the number of layers in the i-th group
*/
std::vector<std::vector<LayerId>> layer_groups_;
/**
* @brief time step of layer groups
* time_steps_.size() == layer_groups_.size()
* time_steps_[i] means the time step of the i-th group
*/
std::vector<BasicTimeStep*> time_steps_;
/**
* @brief shape split sections of layer groups
* shape_secs_.size() == layer_groups_.size()
* shape_secs_[i] means the shape split sections of the i-th group
*/
std::vector<shape_secs_t> shape_secs_;
/**
* @brief the original graph structure
* It will be deprecated in the future.
*/
void* net_graph_;
};
如用户有兴趣,可以联系我们进行深入交流。
内部接口说明¶
我们提供了一些用户在做自定义优化PASS时可能会用到的内部功能接口,详细信息请见头文件 bmcompiler_lg_functions.h里的注释。
Demo示例¶
在$(BMNNSDK)/bmnet/bmcompiler/plugin目录下,我们提供了一个图优化filter和一个后端优化pass的示例。客户在该目录下可以直接敲make来编译plugin,完成后该目录下会生成libbmplugin_optimizer.so。 接着设置环境变量BMCOMPILER_PLUGIN_PATH=$(BMNNSDK)/bmnet/bmcompiler/plugin,然后运行BMNet模型编译器。例如,我们运行的命令是
bmnetu --model caffe_resnet50_bmnetc_deploy_int8_unique_top.prototxt \
--weight caffe_resnet50_bmnetc.int8umodel \
--v=3 --target=BM1684 --opt=1
此时我们可以看到log中会出现下面信息,这说明plugin中提供的图优化filter示例被成功执行了。

然后我们可以在log中找到下面信息,这说明plugin中提供的后端优化Pass示例被成功执行了。
