NNToolChain 基本概念介绍¶
SOPHONSDK
算能原创深度学习开发工具包
BM168x
算能面向深度学习领域推出的张量处理器, 目前支持芯片为BM1684、BM1684X。
PCIE-Mode
一种产品形态,SDK运行于X86平台,BM168x作为PCIE接口的深度学习计算加速卡存在
SOC-Mode
一种产品形态,SDK独立运行于BM168x平台,支持通过千兆以太网与其他设备互联
TPU编译器
是一个面向算能TPU处理器研发的深度神经网络的优化编译器,可以将深度学习框架定义的各种深度神经网络转化为TPU上运行的指令流。
BMRuntime: 匹配BMCompiler的运行时库,提供上层应用程序可编程调用的接口
BMNetC: 面向Caffe model的BMCompiler前端
BMNetT: 面向TensorFlow model的BMCompiler前端
BMNetM: 面向MxNet model的BMCompiler前端
BMNetP: 面向PyTorch model的BMCompiler前端
BMNetD: 面向Darknet model的BMCompiler前端
BMNetU: 面向SOPHGO UFW model的BMCompiler前端
BMNetO: 面向ONNX model的BMCompiler前端
BMPaddle: 面向PaddlePaddle model的BMCompiler前端
BMLang: 面向TPU的高级编程模型,用户开发时无需了解底层TPU硬件信息
BModel: 面向算能TPU处理器的深度神经网络模型文件格式
版本特性¶
SDK包含设备驱动、运行库、头文件和相应工具,主要特性如下:
设备驱动
PCIE支持多种Linux发行版本和Linux内核。
SOC模式提供ko模块,可以直接安装到BM168x SOC Linux Release。
运行库
提供深度学习推理引擎,提供最大的推理吞吐量和最简单的应用部署环境;
提供三层接口,网络级接口/layer级接口/指令级接口
提供运行库编程接口,用户可以直接操作bmlib等底层接口,进行深度的开发
运行库支持多线程、多进程,提供并发处理能力。
工具
提供bmnetc工具,支持Caffe网络模型进行编译
提供bmnett工具, 支持TensorFlow模型进行编译
提供bmnetm工具,支持MxNet模型进行编译
提供bmnetp工具,支持PyTorch模型进行编译
提供bmnetd工具,支持Darknet模型进行编译
提供bmnetu工具,支持SOPHGO UFW模型进行编译
提供bmneto工具,支持ONNX模型进行编译
提供bmpaddle工具,支持PaddlePaddle模型进行编译
提供bm_model.bin工具,查看bmodel文件的参数信息,也可以将bmodel文件进行分解和合并
提供profiling的工具,展示每一层执行所使用的指令和指令所消耗的时间
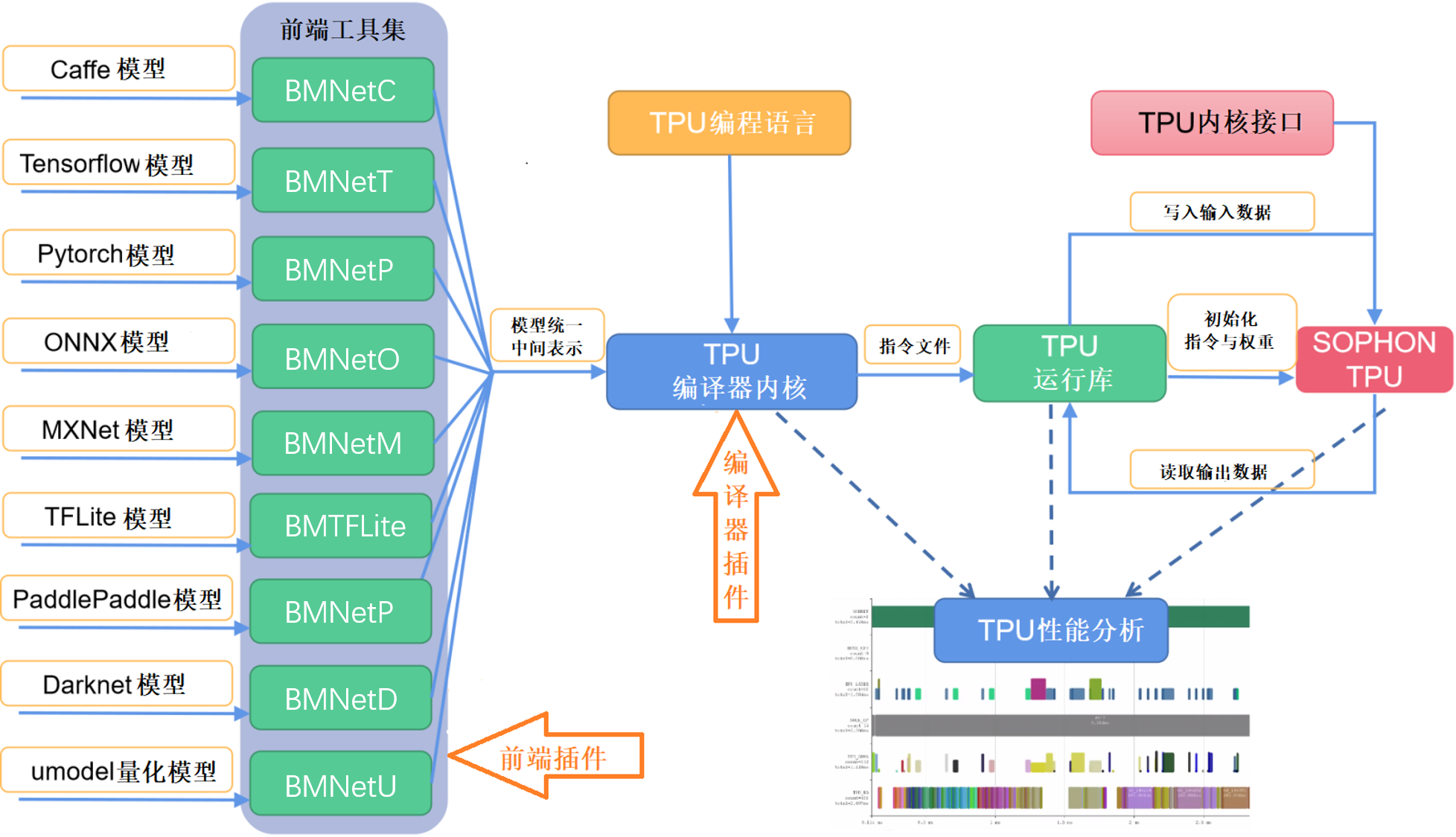
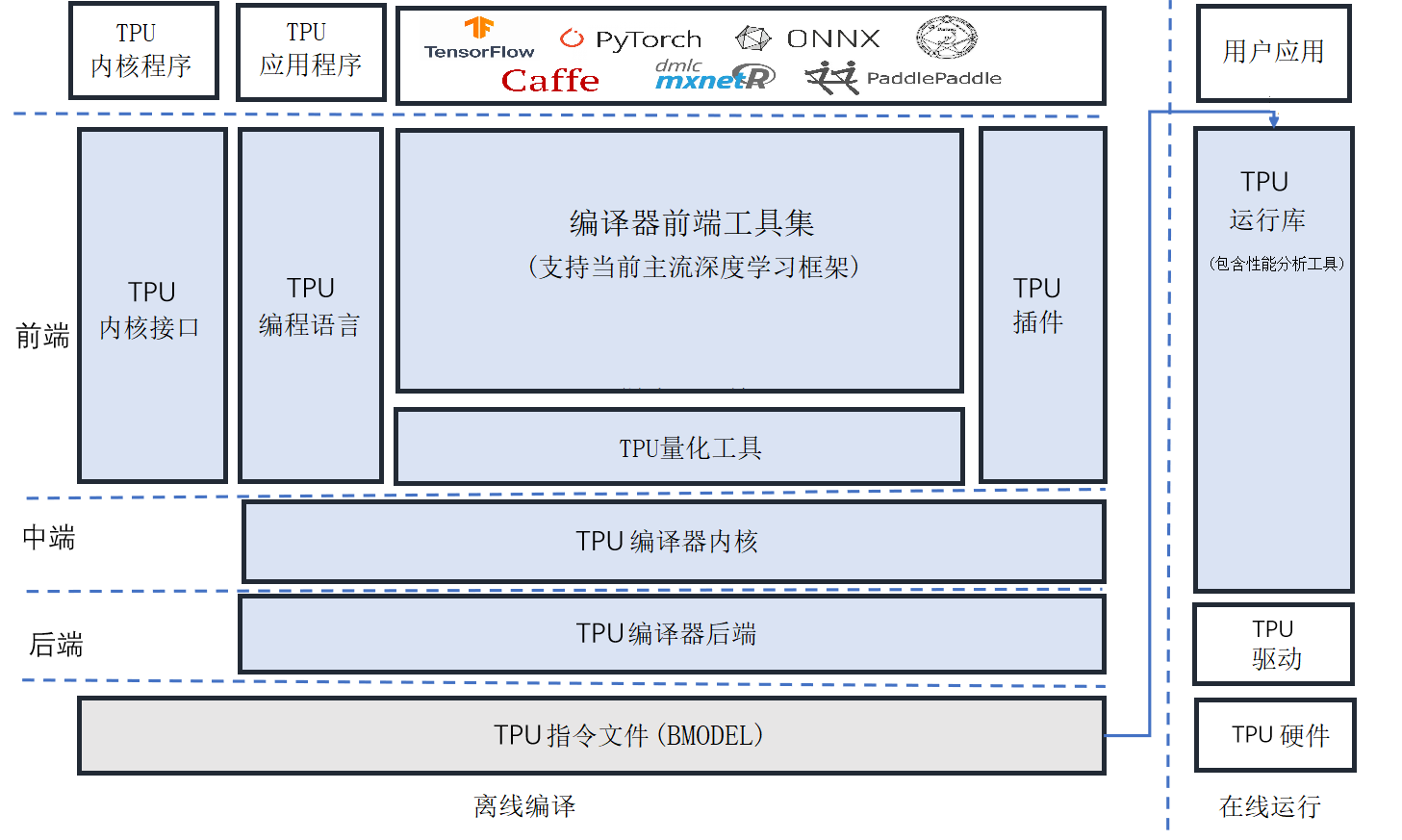
NNToolChain 整体架构¶
SOPHONSDK的NNToolchain是算能基于其自主研发的AI芯片,所定制的深度学习工具链,涵盖了神经网络推理阶段所需的模型优化、高效运行时支持等能力,为深度学习应用开发和部署提供易用、高效的全栈式解决方案。
NNToolchain整体架构如下图所示,由Compiler和Runtime(图中左右)两部分组成。Compiler负责对各种主流深度神经网络模型(如Caffe model、Tensorflow model等)进行编译和优化。Runtime向下屏蔽底层硬件实现细节,驱动TPU芯片,向上为应用程序提供统一的可编程接口,既提供神经网络推理功能,又提供对DNN和CV算法的加速。
NNToolChain工作流程请见下图。首先,Compiler将主流框架模型转换成TPU能够识别的模型格式——bmodel。然后,Runtime读取bmodel,将数据写入TPU供神经网络推理,随后读回TPU处理结果。此外,还允许TPU编程语言构建自定义上层算子和网络,TPU内核接口允许在TPU设备上直接编程。利用TPU性能分析工具还可以对模型进行性能剖析。利用相关的插件机制允许用户扩展前端与优化Pass。