5.1. Model Migration Overview
contents
Chaffeng series TPU platform only supports BModel acceleration. Users need to first carry out model migration and convert the models trained under other frameworks into Bmodels before they can run on Chaffeng Series TPU. Currently SophonSDK supports operators and models under most open source frameworks (Caffe, Darknet, MXNet, ONNX, PyTorch, TensorFlow, Paddle, etc.), and more network layers and models are also being continuously supported. For support for operators and models, see the TPU-NNTC Development Reference Manual.
Deep learning framework |
Version requirement |
The bmnetx model compiler used |
Caffe |
Official version |
bmnetc |
Darknet |
Official version |
bmnetd |
MXNet |
mxnet >= 1.3.0 |
bmnetm |
ONNX |
onnx == 1.7.0 (Opset version == 12) onnxruntime == 1.3.0 protobuf >= 3.8.0 |
bmneto |
PyTorch |
pytorch >= 1.3.0, recommend 1.8.0 |
bmnetp |
TensorFlow |
tensorflow >= 1.10.0 |
bmnett |
Paddle Paddle |
paddlepaddle >= 2.1.1 |
bmpaddle |
We provide the TPU-NNTC toolchain to help users achieve model migration. For the BM1684/BM1684X platform, it supports both float32 and int8 quantized models. The model conversion process and chapter introduction are shown in the figure:
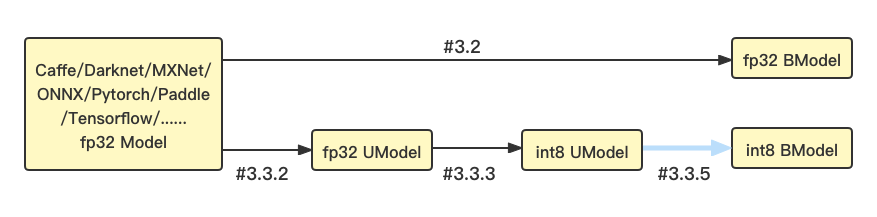
If you need to run the fp32 BModel, refer to section 3.2 FP32 Model Generation.
To run in8 BModel, prepare quantized data sets, convert the original model to fp32 UModel, use the quantization tool to quantify it to int8 UModel, and compile it to int8 BModel using bmnetu. For details, see 3.3 INT8 Model Generation.
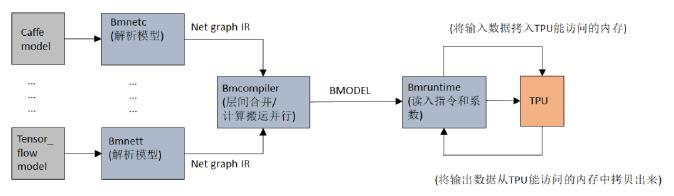
The TPU-NNTC tool chain provides tools such as bmnetc, bmnetd, bmnetm, bmneto, bmnetp, bmnett, and bmnetu. It is used to convert models under Caffe, Darknet, MXNet, ONNX, Pytorch, Tensorflow, UFramework (a customized model intermediate format framework), etc. : After being parsed by front-end tools, BMNet Compiler converts models of various frameworks offline, generates instruction flows that TPU can execute, and serializes them into BModel files. When online inference is performed, BMRuntime is responsible for reading BModel model, copy transmission of data, execution of TPU inference and reading of calculation results, etc.
注解
When the network layer or operator required by the user model is not supported by SophonSDK and a user-defined operator or layer needs to be developed, you can use the BMNET front-end plug-in to add a user-defined layer or operator on the basis of the provided BMNET model compiler. The following ways of implementing custom layers or operators are currently supported:
Based on BMLang development: BMLang is an upper-level programming language for Sophon TPU, which is suitable for writing high-performance algorithms such as deep learning, image processing and matrix arithmetic programs. We provide two BMLang programming interfaces based on C++ and Python. For details, see BMLang_cpp Technical Reference Manual and BMLang_python Technical Reference Manual in tpu-nntc/doc in the SDK.
Development based on TPUKernel: TPUKernel is an underlying programming model for Sophon TPU, which provides the programmable capability of the chip to the maximum extent through a set of atomic operation interfaces encapsulated according to the underlying instruction set of the chip. For details, please refer to the TPUKernelUser Development Document.
If you encounter problems during the use, please contact Computer technology for technical support.