5.3. INT8 Model Generation
contents
The BM168X supports deployment of INT8 quantized models. In the general process, it is necessary to quantify the fp32 model with the help of quantization tools provided by computational energy. Qantization-Tools under the TPU-NNTC tool chain is a network model quantization tool independently developed by computational technology. It analyzes various trained 32bit floating point network models and generates 8bit fixed point network models. The 8bit fixed point network model can be applied to SOPHON series AI computing platform. On the SOPHON platform, the input, output and coefficient of each layer of the network are represented by 8 bits, which significantly reduces power consumption, memory and transmission delay while ensuring network accuracy, and greatly increases the operation speed.
Quantization-Tools consists of three parts: Parse-Tools, Calibration-Tools and U-FrameWork, as shown in the figure below:
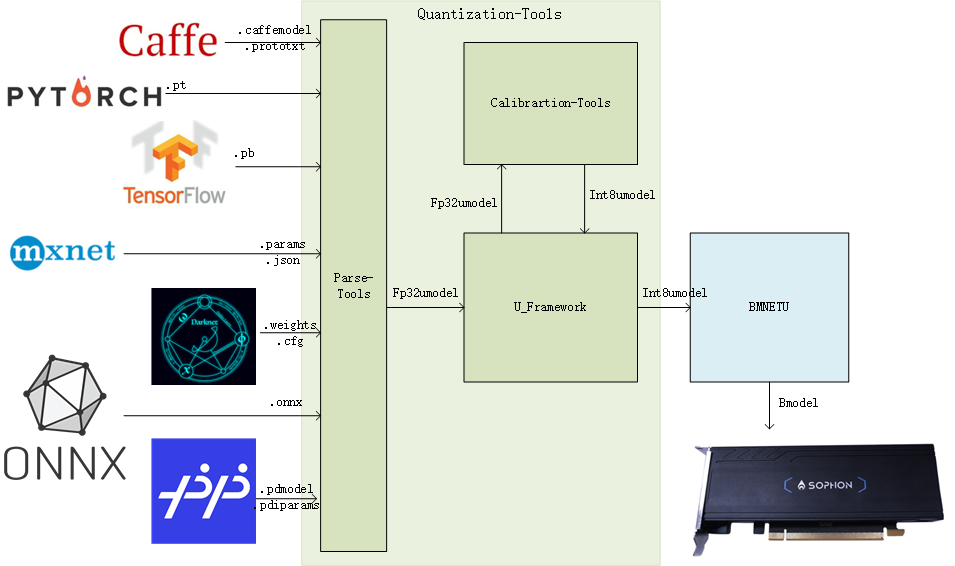
Parse-Tools:
The trained network models under each deep learning framework are analyzed, and a unified format network model file – umodel is generated. The supported deep learning frameworks include Caffe, TensorFlow, MxNet, PyTorch, Darknet, ONNX, and PaddlePaddle.
Calibration-Tools:
Analyze the umodel file in float32 format. By default, the network coefficients are converted to 8bit based on the minimum entropy loss algorithm (MAX and other algorithms are optional). Finally, the network model is saved to an int8 format umodel file.
U-FrameWork:
The self-defined deep learning reasoning framework integrates the computing functions of all open source deep learning frameworks, and provides the following functions:
As a basic computing platform, it provides basic computing for fixed-point.
As a verification platform, it can verify the accuracy of fp32, int8 format network model.
Using bmnetu as an interface, int8umodel can be compiled into a bmodel running on SOPHON computing platform.
The Quantization network process using Quantization-Tools is shown in the following figure:
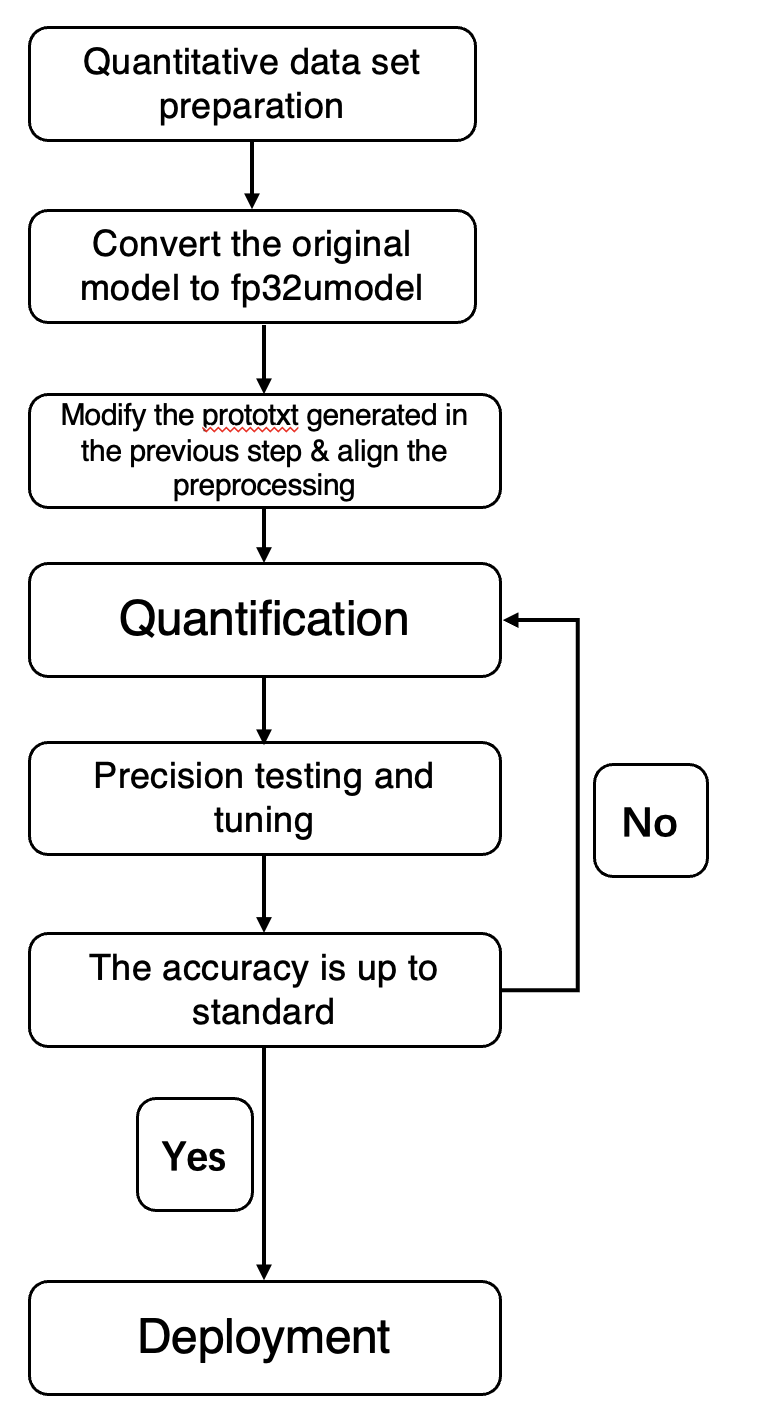
The following steps are typically required to generate int8 quantization models:
Prepare lmdb data set;
Generate fp32 Umodel;
Generate int8 Umodel;
int8 Umodel Accuracy Test (Optional).
Generate int8 Bmodel.
5.3.1. Prepare the lmdb data set
We need to convert the original quantized data set into lmdb format for use by the Quantization-tools for subsequent calibration.
注解
Quantization-tools’ requirements for data formats:
The Quantization-tools requires the format of input data to be [N,C,H,W] : that is, data is first stored according to W, then H, and so on
Quantization-tools stores the C dimension of input data in the same order as the original framework. For example, the C dimension of caffe is stored in BGR order. tensorflow requires that the C dimension be stored in RGB
There are two ways to convert data into lmdb datasets:
Use the auto_cali one click quantization tool to convert the picture catalog into lmdb for quantization step by step;
Use U-FrameWork interface to capture network reasoning input during network reasoning process or write scripts to save lmdb. For details, see create_lmdb. The functionality associated with LMDB has been made into the ufwio package, which no longer relies on SophonSDK and can run in any Python3.5 or later environment.
In the U-FrameWork, the input data of the network is saved in the form of LMDB, which serves as the data source of the data layer. It is recommended that pre-processing operations, such as mean reduction and variance reduction, be performed during LMDB production. The pre-processing data is stored in lmdb. In the case of complex processing that cannot be accurately expressed by preprocessing, or in the case that intermediate results need to be trained as the input of the next level network in the cascaded network, users can develop their own preprocessing scripts to directly generate lmdb.
SophonSDK provides a ufwio package that provides a series of apis to help users build LMDB. This package has been decoupled from SophonSDK and can be installed and run in any Pyhton3.5 or above environment. For details, please refer to TPU-NNTC Development Reference Manual to prepare LMDB data set.
Example 2: create_lmdb_demo is provided in TPU-NNTC Development Reference Manual. This example program can be used as a tool or you can add custom preprocessing on it.
5.3.2. Generate FP32 Umodel
In order to quantify the network models trained by the third party framework, it is necessary to convert them into the private format of the quantization platform fp32 Umodel.
注解
This stage generates a ‘.fp32umodel’ file and a ‘.Prototxt’ file.
prototxt file name is usually net_name_bmnetX_test_fp32.prototxt, where X represents the first letter of the original framework name, For example, prototxt will be net_name_bmnett_test_fp32.prototxt after TensorFlow network is converted to Umodel. The PyTorch transformed network will be net_name_bmnetp_test_fp32.prototxt, etc.
The fp32umodel file generated at this stage is the quantized input, and the modification preprocessing in using-lmdb is the modification of prototxt file generated at this stage.
注意
Attention: The fp32 umodel based on Calibration-tools needs to keep BatchNorm layer and Scale layer independent. When you use third-party tools to do some equivalent transformation optimizations on the network graph, make sure that the BatchNorm and Scale layers are not pre-merged into Convolution.
注意
Note the parameter Settings in this phase:
If -D (-dataset) is specified, ensure that the path under -D is correct and the specified dataset is compatible with the network. Otherwise, a running error may occur.
- If -D is specified, modify prototxt according to section using-lmdb.
Use the data layer as input
Set up data preprocessing correctly
Set the lmdb path correctly
When no valid data source is available, the -D parameter should not be used. (This parameter is optional and does not specify that random data will be used to test the correctness of network conversion. You can manually modify the data source in the converted network.)
When transforming the model, you can specify the parameter “–cmp”. Using this parameter, you can compare whether the intermediate format of model transformation is consistent with the calculation results of the model under the original framework, which increases the correctness verification of model transformation.
The tools used to generate fp32 umodel at this stage are a series of python scripts named ufw.tools.*_to_umodel, which are stored in the ufw package. * indicates the abbreviation of different frameworks.
1# Caffe model converts the fp32umodel tool
2python3 -m ufw.tools.cf_to_umodel --help
3# Darknet Model conversion tool fp32umodel
4python3 -m ufw.tools.dn_to_umodel --help
5# MxNet model conversion fp32umodel tool
6python3 -m ufw.tools.mx_to_umodel --help
7# ONNX model conversion fp32umodel tool
8python3 -m ufw.tools.on_to_umodel --help
9# PyTorch model conversion fp32umodel tool
10python3 -m ufw.tools.pt_to_umodel --help
11# TensorFlow model conversion fp32umodel tool
12python3 -m ufw.tools.tf_to_umodel --help
13#PaddlePaddle model transforms fp32umdoel tool
14python3 -m ufw.tools.pp_to_umodel --help
The detailed parameter description varies depending on the framework. Users can refer to the sample program provided in TPU-NNTC Development Reference Manual, and modify a few parameters to complete their own model transformation. For more information, see TPU-NNTC Development Reference Manual.
5.3.3. Generate INT8 Umodel:
This process converts from fp32 Umodel to int8 Umodel, which is the quantization process. The network quantization process consists of the following two steps:
Optimize the network: Optimize the input floating-point network diagram
Quantized network: floating-point network is quantized to obtain int8 network diagram and coefficient file
Quantization requires lmdb data set generated in 3.3.1 Prepare lmdb Data Set. Because it’s important to use the data set correctly, I’ll explain how to use the data set first.
post-training quantitative method aims to calculate the input and output data range of each layer by reasoning the trained model for a certain number of times, so as to determine the quantitative parameters. To make the statistics as accurate as possible, The inference must ensure that the input data is valid during the actual training/verification, and that the pre-processing is consistent with the training .
The Uframework provides a simple pre-processing interface to pre-process the generated lmdb data to align the pre-processing in the training process. To be specific, you can configure the pre-processing algorithm by modifying the *_test_fp32.prototxt file generated when generating the fp32 umodel. The generated lmdb data will be calculated according to the configuration here before entering the network, and then the real network reasoning will be carried out. The complete preprocessing can be regarded as a combination of the preprocessing performed during lmdb production and the preprocessing algorithm defined in prototxt.
5.3.3.1. Data preprocessing
Generally, the following three modifications should be made before the complete definition:
Use the Data layer as input to the network
Make the data_param parameter of the Data layer point to the location of the generated lmdb dataset
Modify the transform_param parameter of the Data layer to correspond to the network preprocessing of the image
The typical structure of the data_layer is shown in the following example:
1layer {
2name: "data"
3type: "Data"
4top: "data"
5top: "label"
6include {
7 phase: TEST
8}
9transform_param {
10 transform_op {
11 op: RESIZE
12 resize_h: 331
13 resize_w: 331
14 }
15 transform_op {
16 op: STAND
17 mean_value: 128
18 mean_value: 128
19 mean_value: 128
20 scale: 0.0078125
21 }
22}
23data_param {
24 source: "/my_lmdb"
25 batch_size: 0
26 backend: LMDB
27}
28}
For example:
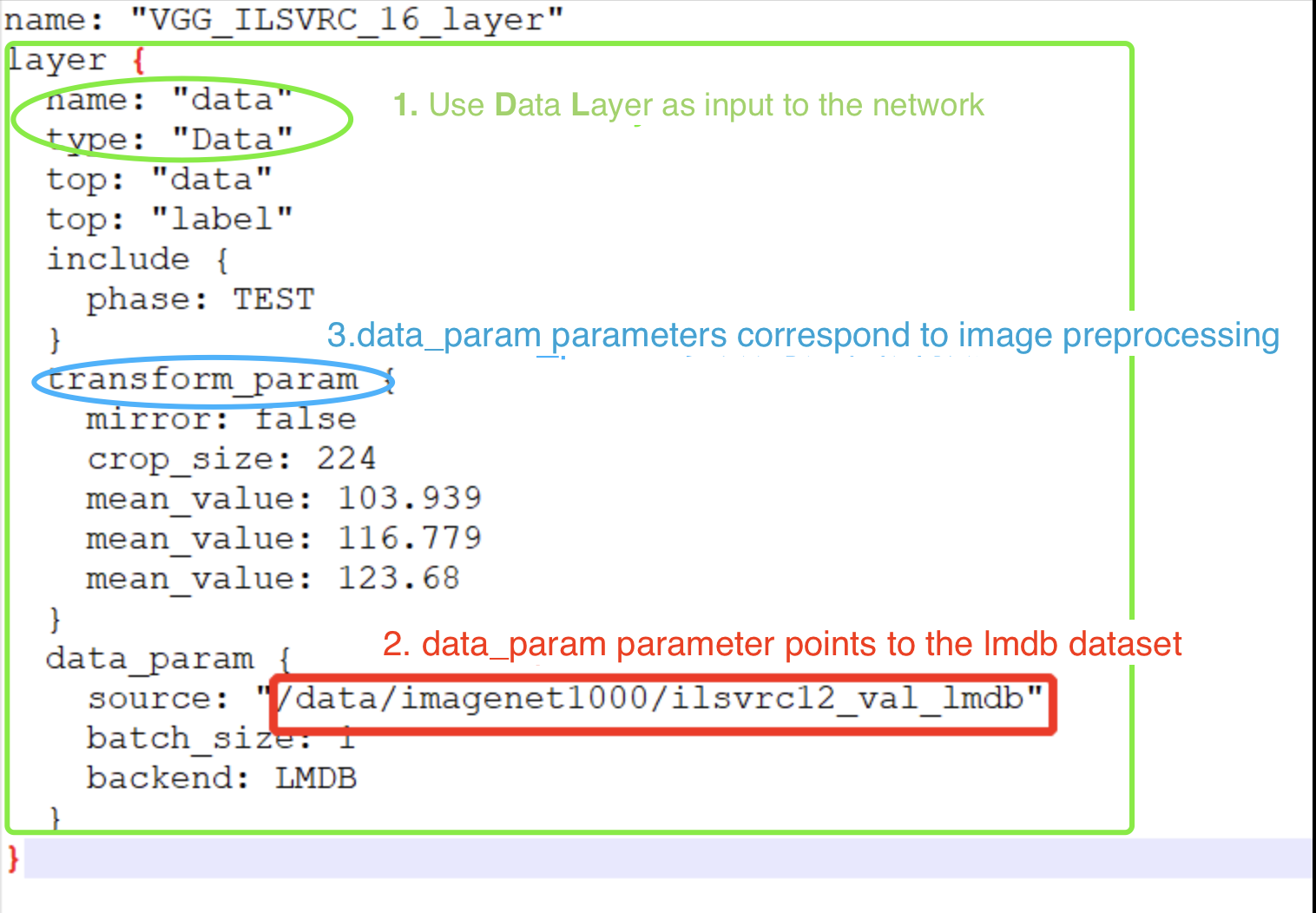
Before quantifying the network, it is necessary to modify the *_test_fp32.prototxt file of the network and add its data preprocessing parameters to the datalayer (or AnnotatedData layer), so as to ensure that the data sent to the network is consistent with the preprocessing when the network is trained in the original framework.
Calibration-tool supports two methods of data preprocessing:
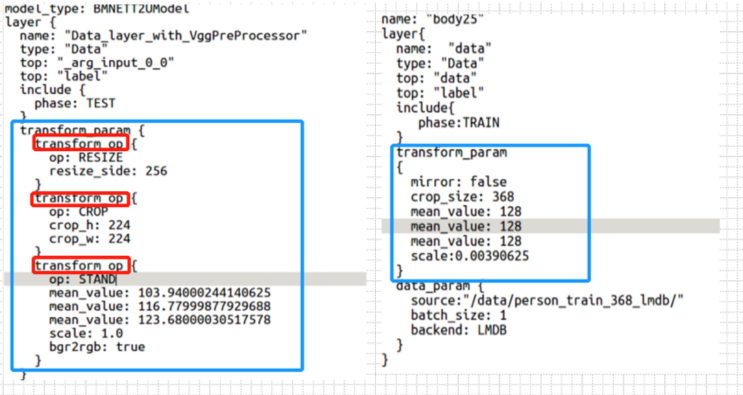
TransformationParameter Specifies the parameter representation of Caffe: The execution order of each parameter in Caffe’s own representation method is relatively fixed (as shown in the right half of the figure above), but it is difficult to fully express the flexible preprocessing modes in Python frameworks such as Tensorflow and Pytorch, which only applies to the default data preprocessing mode of Caffe model. In this way, the preprocessing operations and parameters are defined directly as parameters to transform_param.
Computationally custom TransformOp array representation: We define the transform_op structure, and we decompose the preprocessing we need into different Transform_ops, listed in transform_param in order, and the program performs the calculations separately in order.
注意
When modifying prototxt files to add data preprocessing, you can only define preprocessing using transform_param or transform_op. Please use transform_op first.
For more details about transform_param and transform_op, see the TransformOp definition in the TPU-NNTC Development Reference Manual.
In the current version, lmdb is updated. lmdb is only provided with a python interface. The sample program create_lmdb provides routines that can be modified based on it. It is recommended to include preprocessing in python code, generating preprocessed data for quantization, so that preprocessing does not have to be defined in prototxt. When lmdb is used as the input parameter -D of fp32umodel command, batch_size parameter of data layer above prototxt will be automatically set to 0. If the -D parameter is not specified during the conversion of fp32umodel, note that batch_size is set to 0 when you manually modify the data source specified by prototxt. The binary lmdb generated by the convert_imageset tool of previous versions is compatible with the previous prototxt.
5.3.3.2. Quantization network
Use calibration_use_pb the network can be quantified. For details, refer to TPU-NNTC Development Reference Manual to quantify the network.
5.3.3.3. Optimized network
Use calibration_use_pb can complete the optimization of the network, the default configuration of the input floating-point network optimization, including: batchnorm and scale merge, pre-processing fusion into the network, delete unnecessary operators in the reasoning process and other functions.For details, refer to TPU-NNTC Development Reference Manual to optimize the network.
5.3.3.4. Cascade network quantization
提示
Cascade network quantization Quantization of cascaded networks requires quantization of each network, LMDB preparation and quantization tuning for each network.
5.3.4. Accuracy test
Precision testing is an optional step to verify the accuracy of the network after int8 quantization.
This step can be scheduled before the deployment of the network described and repeated with the quantization network to achieve the desired accuracy.
Accuracy testing may vary depending on the network type, and often means complete pre - and post-processing and precision calculation program development.
Pk-tools provides a UFramework application interface to compute network inference precision by using float32 or int8 reasoning.
注解
After generating a new int8 bmodel, the network may need to verify accuracy losses. The SDK provides a way to compare accuracy for different types of networks.
Classification network, by modifying the network output layer to add top-k: refer to TPU-NNTC Development Reference Manual classification network accuracy test.
Test the network, test the specific picture through the ufw, and compare with the fp32 network: Check the accuracy test of the network by referring to TPU-NNTC Development Reference Manual.
Check the accuracy difference through the graphical interface: refer to the TPU-NNTC Development Reference Manual quantitative error qualitative analysis.
For more information on accuracy testing, quantization error analysis and quantization techniques, please refer to TPU-NNTC Development Reference Manual
5.3.5. Generate INT8 Bmodel
int8umodel is a temporary intermediate form that needs to be further converted into an int8 bmodel that can be executed on the computational AI platform. This section can be regarded as an int8umodel deployment operation or an int8 bmodel generation operation.
By using the BMNETU tool provided by the SDK, you can convert INT8 Umodel (below), the output of 3.3.3 Generate INT8 Umodel, into int8 bmodel easily and quickly.
1**.int8umodel,
2**_deploy_int8_unique_top.prototxt
BMNETU is a Unified Framework (UFW) Model compiler for BM1684. It can compile Unified Model (umodel) and prototxt of a network into files required by BMRuntime. In addition, the NPU model calculation results of each layer can be compared with the CPU calculation results to ensure correctness. For details, see TPU-NNTC Development Reference Manual used by BMNETU.
5.3.6. auto_cali one-click quantization tool
It is recommended to use auto_cali as a key quantization tool for CV inference network which usually takes pictures as input. This tool is a step quantization integration, and the operation is simpler. LMDB data sets or original pictures can be used to complete quantization, which can reduce errors caused by manual input in the step quantization process. Its functions are as follows:
One key from the original framework (TensorFlow/PyTorch/Caffe Darknet/MxNet/PaddlePaddle/ONNX) to BM1684 / BM1684X bmodel conversion chip.
Quantization strategy can be searched automatically according to int8 model precision results according to preset optimization parameter combination to find the best quantization strategy meeting the accuracy requirements.
For details, please refer to auto_cali in TPU-NNTC Development Reference Manual.