5.1. 模型迁移概述
目录
算丰系列TPU平台仅支持BModel模型加速,用户需要首先进行模型迁移,把其他框架下训练好的模型转换为BModel才能在算丰系列TPU上运行。 当前SophonSDK已支持绝大部分开源框架(Caffe、Darknet、MXNet、ONNX、PyTorch、TensorFlow、Paddle Paddle等)下的算子和模型,更多的网络层和模型也在持续支持中。关于对算子和模型的支持情况,请查看《 TPU-NNTC开发参考手册 》。
深度学习框架 |
版本要求 |
使用的bmnetx模型编译器 |
Caffe |
官方版本 |
bmnetc |
Darknet |
官方版本 |
bmnetd |
MXNet |
mxnet >= 1.3.0 |
bmnetm |
ONNX |
onnx == 1.7.0 (Opset version == 12) onnxruntime == 1.3.0 protobuf >= 3.8.0 |
bmneto |
PyTorch |
pytorch >= 1.3.0, 建议1.8.0 |
bmnetp |
TensorFlow |
tensorflow >= 1.10.0 |
bmnett |
Paddle Paddle |
paddlepaddle >= 2.1.1 |
bmpaddle |
我们提供了TPU-NNTC工具链帮助用户实现模型迁移。对于BM1684/BM1684X平台来说,它既支持float32模型,也支持int8量化模型。其模型转换流程以及章节介绍如图:
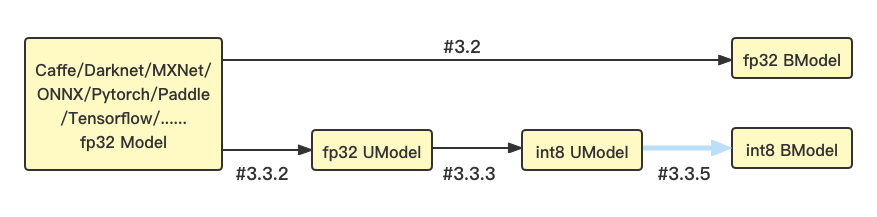
如果需要运行fp32 BModel,请参考3.2 FP32模型生成章节。
如果需要运行in8 BModel,需要先准备量化数据集、将原始模型转换为fp32 UModel、再使用量化工具量化为int8 UModel、最后使用bmnetu编译为int8 BModel,具体请依次参考3.3 INT8模型生成章节。
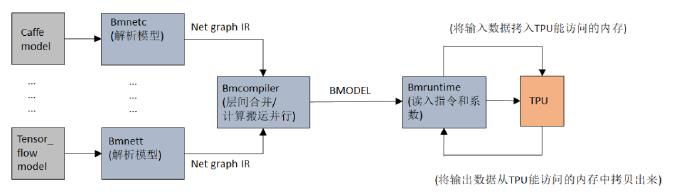
TPU-NNTC工具链提供了bmnetc、bmnetd、bmnetm、bmneto、bmnetp、bmnett、bmnetu等工具,分别用来转换Caffe、Darknet、MXNet、ONNX、Pytorch、Tensorflow、UFramework(算能科技自定义的模型中间格式框架)等框架下的模型:经前端工具解析后,模型编译器BMNet Compiler会对各种框架的模型进行离线转换,生成 TPU 能够执行的指令流并序列化保存为BModel文件;当执行在线推理时, 由BMRuntime负责BModel模型的读取、数据的拷贝传输、TPU推理的执行以及计算结果的读取等。
注解
当用户模型中所需要使用的网络层或算子不被 SophonSDK 所支持,需要开发自定义算子或层时,可以使用我们提供的 BMNET 前端插件,在已提供的 BMNET 模型编译器的基础上增加用户自定义层或者算子。目前支持以下几种实现自定义层或算子的方式:
基于BMLang开发: BMLang 是一种面向 Sophon TPU 的上层编程语言,适用于编写高性能的深度学习、图像处理、矩阵运算等算法程序。我们提供了基于 C++ 和基于 Python 两种 BMLang 编程接口。详情请参考SDK中 tpu-nntc/doc 目录下的《 BMLang_cpp技术参考手册 》和 《 BMLang_python技术参考手册 》。
基于TPUKernel开发: TPUKernel 是面向用户推出的针对 Sophon TPU 的底层编程模型,通过根据芯片底层指令集封装的一套原子操作接口,向用户最大程度提供芯片的可编程能力。详情请参考《 TPUKernel用户开发文档 》。
若您在使用过程中遇到问题,可联系算能科技获取技术支持。