概述
本例主要是利用resnet18模型,实现一个完整的分类应用。 本例模型和代码在 http://219.142.246.77:65000/sharing/NVUS3acJ7
下载到本地 resnet18_classify.tar.gz,并解压:
tar zxvf resnet18_classify.tar.gz
resnet18_classify目录中包含以下文件:
model/resnet18.onnx resnet18原始模型
images/ 测试图片集
ILSVRC2012/ 量化用数据集
scripts/ 本示例中脚本文件
src/ 应用源码目录
CMakeLists.txt 构建脚本
编译与量化模型
初始化tpu-nntc环境
在 docker 环境使用工具链软件,最新版本的 docker 可以参考 官方教程 进行安装。安装完成后,执行下面的脚本将当前用户加入 docker 组,获得 docker 执行权限。
sudo usermod -aG docker $USER
newgrp docker
从官网上下载tpu-nntc的压缩包,命名如 tpu-nntc_vx.y.z-<hash>-<date>.tar.gz
mkdir tpu-nntc
# 将压缩包解压到tpu-nntc
tar zxvf tpu-nntc_vx.y.z-<hash>-<date>.tar.gz --strip-components=1 -C tpu-nntc
tpu-nntc使用的docker是sophgo/tpuc_dev:v2.1, docker镜像和tpu-nntc有绑定关系,少数情况下有可能更新了tpu-nntc,需要新的镜像
cd tpu-nntc
# 进入docker,如果当前系统没有对应镜像,会自动从docker hub上下载
# 将tpu-nntc的上一级目录映射到docker内的/workspace目录
# 这里用了8001到8001端口映射,之后在使用ufw可视化工具会用到
# 如果端口已经占用,请更换其他未占用端口,后面根据需要更换进行调整
docker run -v $PWD/..:/workspace -p 8001:8001 -it sophgo/tpuc_dev:v2.1
# 此时已经进入docker,并在/workspace目录下
# 下面初始化软件环境
cd /workspace/tpu-nntc
source scripts/envsetup.sh
其他docker初始化方式:
如果是离线环境,可以先提前下载,然后导入到目标机上,命令如下:
# 在可以联网的机器上, 保存镜像 docker pull sophgo/tpuc_dev:v2.1 docker save sophgo/tpuc_dev:v2.1 -o sophon_tpuc_dev.docker # 将sophon_tpuc_dev_docker.tar复制到目标机器上后 docker load -i sophon_tpuc_dev.docker此外,tpu-nntc在scripts目录提供了docker_setup.sh脚本, 供参考和方便基本使用,实际使用中可根据需求自行管理。使用方法如下:
# docker_setup.sh 后面参数来指定哪个目录作为工作目录,映射到docker里的/workspace # 这里用 tpu-nntc 的上一级目录 scripts/docker_setup.sh .. # 会输出以下信息,如果8001端口占用,会自动选择其他未占用端口 # ... # OPEN 'http://localhost:8001' IN WEB BROWSER WHEN 'python3 -m ufw.tools.app' RUNNING IN DOCKER
注意:此时 resnet18_classify 目录与 tpu-nntc 目录是并列的。将 resnet18_classify 放到其他目录也是可以的,但要注意调整后文相关的命令。
环境初始化完成后,进入resnet18_classify目录:
cd /workspace/resnet18_classify
# 为了方便清理,建议创建一个空的工作目录
mkdir -p workdir && cd workdir
编译FP32 BMODEL
由于转换的是onnx模型,所以需要bmneto前端,转换命令如下:
# 此时在resnet18_classify/workdir目录中
python3 -m bmneto --model ../model/resnet18.onnx \
--input_names "input" \
--shapes "[[1,3,224,224]]" \
--target BM1684X \
--outdir bmodel/fp32
--target 用于指定芯片型号,目前支持 BM1684 和 BM1684X 。
查看下fp32 bmodel的信息:
tpu_model --info bmodel/fp32/compilation.bmodel
输出模型信息如下:
bmodel version: B.2.2
chip: BM1684X
create time: Thu Jul 21 06:14:45 2022
==========================================
net 0: [network] static
------------
stage 0:
input: input, [1, 3, 224, 224], float32, scale: 1
output: output, [1, 1000], float32, scale: 1
device mem size: 49782688 (coeff: 46968736, instruct: 0, runtime: 2813952)
host mem size: 0 (coeff: 0, runtime: 0)
自动量化生成INT8 BMODEL
自动量化工具会自动处理图片数据集将其转为lmdb数据集,并使用不同量化策略量化多次,自动生成bmodel。
本例中,量化采用了ILSVRC2012的部分图片。
mkdir -p auto_cali_out
# 注意cali_image_preprocess参数,要和模型原始应用的预处理一致
# 否则会出现模型量化精度高,但在应用上精度低的情况
python3 -m ufw.cali.cali_model \
--net_name "resnet18" \
--model ../model/resnet18.onnx \
--cali_image_path ../ILSVRC2012/ \
--cali_image_preprocess '
resize_h=224,resize_w=224;
mean_value=123.675:116.28:103.53;
scale=0.0171:0.0175:0.0174;
bgr2rgb=True' \
--input_names 'input' \
--input_shapes '[1,3,224,224]' \
--target BM1684X \
--outdir auto_cali_out
cp -r auto_cali_out/resnet18_batch1 bmodel/auto-int8
--target 用于指定芯片型号,目前支持 BM1684 和 BM1684X 。
查看下 bmodel 的信息:
tpu_model --info bmodel/auto-int8/compilation.bmodel
输出如下, 可以看到输入和输出类型是 int8:
bmodel version: B.2.2
chip: BM1684X
create time: Thu Jul 21 06:37:36 2022
==========================================
net 0: [resnet18] static
------------
stage 0:
input: input, [1, 3, 224, 224], int8, scale: 48.21
output: output, [1, 1000], int8, scale: 0.214865
device mem size: 14270368 (coeff: 12009376, instruct: 0, runtime: 2260992)
host mem size: 0 (coeff: 0, runtime: 0)
# 查看量化精度情况(可选)
python3 -m ufw.tools.app --port 8001
这时在本机的 8001 端口(启动docker时显示的端口)可以打开网页,如果是本机直接打开 http://localhost:8001 ,如果是远程服务器请将 localhost 替换成服务器 IP。按图中(1)(2)步操作,等待程序运行完成,可以看到如下结果:
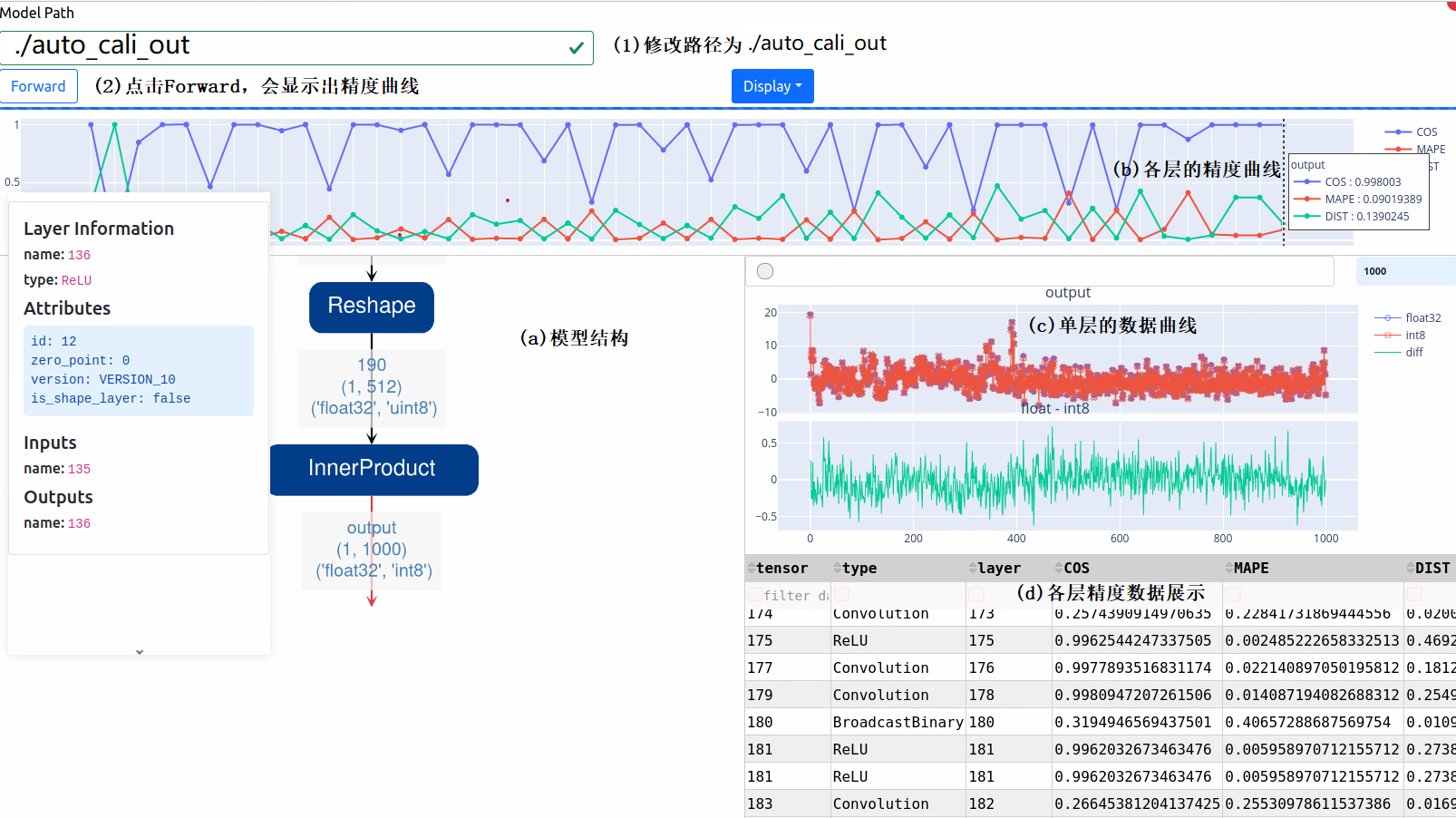
图中(a)(b)(c)(d)说明了各部分的作用。从图中可以看到,最终的余弦距离已经达到0.998003,能够保证分类结果的单调性,从而保证分类的准确性。
注意:这里可视化工具是在量化数据集中随机找一张图进行一次推理,并把数据显示出来。每次显示时会不一样,但比较接近。
如果最终精度或在业务上验证精度不满足要求,可以考虑增加迭代次数或其他参数。
回到开发环境,Ctrl+C结束精度显示服务。
分步量化生成INT8 BMODEL(可选)
分步量化步骤相对较多,但很多的细节可控,如调整模型结构,按layer来指定量化参数等,需要一定的经验和技巧,通常是应对复杂结构的网络。这里只介绍基本的命令和步骤,具体可以参考我们的开发手册。
生成LMDB的输入数据
图片数据集生成lmdb脚本可以参考../scripts/convert_imageset.py,主要功能是调用opencv进行预处理,然后保存成lmdb。在这里直接使用该脚本转换:
python3 ../scripts/convert_imageset.py \
--imageset_rootfolder=../ILSVRC2012 \
--imageset_lmdbfolder=./image_lmdb \
--resize_height=224 \
--resize_width=224 \
--shuffle=True \
--mean=[123.675,116.28,103.53] \
--scale=[0.0171,0.0175,0.0174] \
--bgr2rgb=True \
--gray=False
运行完成后会在当前目录下生成image_lmdb/data.mdb文件。该文件由于存储的是解码后的数据,相对原来图片总大小,会大很多。
导出FP32 UMODEL
# 此时在resnet18_classify/workdir目录中
# 注意和编译FP32 bmodel相比,增加了--mode GenUmodel参数,并且--target是无用的
# 此步会生成umodel/network_bmneto.fp32umodel
python3 -m bmneto --model ../model/resnet18.onnx \
--mode GenUmodel \
--input_names "input" \
--shapes "[[1,3,224,224]]" \
--outdir umodel
# 此步将umodel/network_bmneto.fp32umodel中的模型结构生成出来,并设定数据集为之前生成的image_lmdb
# 会生成umodel/network_bmneto_test_fp32.prototxt
python3 -m ufw.tools.to_umodel \
-u umodel/network_bmneto.fp32umodel \
-D image_lmdb
这里需要说明一下,完整的FP32 UMODEL包含.prototxt和.fp32umodel两个文件, 其中:
prototxt文件用于描述网络结构,并且会将数据集路径、前处理一些过程保存到里面, 也可以手工精调每层的量化参数
fp32umodel主要用于保存网络权重。
量化FP32 UMODEL为INT8 UMODEL
# 这里迭代了50次
# save_test_proto 用于生成可视化数据,如果没加,会无法可视化结果,但不会影响量化过程
calibration_use_pb quantize \
--model umodel/network_bmneto_test_fp32.prototxt \
--weights umodel/network_bmneto.fp32umodel \
--target BM1684X \
--iterations=50 \
--save_test_proto=true
--target 用于指定芯片型号,目前支持 BM1684 和 BM1684X 。
量化完成后,会在umodel目录生成network_bmneto_deploy_int8_unique_top.prototxt和network_bmneto.int8umodel两个文件,作为INT8 UMODEL, 最终编译会用到。
之后,也可以进行可视化显示。
# 查看量化精度情况(可选)
python3 -m ufw.tools.app --port 8001
同时在浏览器中打开http://localhost:8001(docker初始化时显示的端口),按图中(1)(2)步操作,等待程序运行完成,可以看到如下结果:

可以看到余弦距离达到0.986552,满足分类要求。
回到开发环境,Ctrl+C结束精度显示服务。
编译出INT8 BMODEL
将umodel转换为bmodel要用到bmnetu工具:
bmnetu --model umodel/network_bmneto_deploy_int8_unique_top.prototxt \
--weight umodel/network_bmneto.int8umodel \
--target BM1684X \
--outdir "bmodel/step-int8"
--target 用于指定芯片型号,目前支持 BM1684 和 BM1684X 。
查看下bmodel的信息:
tpu_model --info bmodel/step-int8/compilation.bmodel
输出如下, 可以看到输入和输出类型是int8:
bmodel version: B.2.2
chip: BM1684X
create time: Thu Jul 21 10:59:22 2022
==========================================
net 0: [network_bmneto] static
------------
stage 0:
input: input, [1, 3, 224, 224], int8, scale: 52.3023
output: output, [1, 1000], int8, scale: 0.197092
device mem size: 12771232 (coeff: 12009376, instruct: 0, runtime: 761856)
host mem size: 0 (coeff: 0, runtime: 0)
清理环境
完成所有bmodel生成工作后,可以退出tpu-nntc环境。
exit
程序开发部署
安装libsophon环境
请参考 libsophon 使用手册安装 libsophon。 此外,由于本例的前处理用到了opencv的库,建议安装libopencv-dev。
sudo apt install libopencv-dev
检查BMODEL正确性和性能
安装好libsophon后,可以使用bmrt_test来测试编译出的bmodel的正确性及性能。
可以根据bmrt_test输出的性能结果,来估算模型最大的fps,来选择合适的模型
# 下面测试上面编译出的bmodel
# --context_dir参数后面接文件夹,里面必须有compilation.bmodel、input_ref_data.dat、output_ref.data.dat, 后面两个文件是编译时产生,用于运行时做数据比对
cd resnet18_classify/workdir
bmrt_test --context_dir bmodel/fp32
bmrt_test --context_dir bmodel/auto-int8
bmrt_test --context_dir bmodel/step-int8
以最后一个命令输出为例:
01 [BMRT][load_bmodel:1019] INFO:Loading bmodel from [bmodel/step-int8//compilation.bmodel]. Thanks for your patience...
02 [BMRT][load_bmodel:983] INFO:pre net num: 0, load net num: 1
03 [BMRT][show_net_info:1358] INFO: ########################
04 [BMRT][show_net_info:1359] INFO: NetName: network_bmneto, Index=0
05 [BMRT][show_net_info:1361] INFO: ---- stage 0 ----
06 [BMRT][show_net_info:1364] INFO: Input 0) 'input' shape=[ 1 3 224 224 ] dtype=INT8 scale=52.3023
07 [BMRT][show_net_info:1373] INFO: Output 0) 'output' shape=[ 1 1000 ] dtype=INT8 scale=0.197092
08 [BMRT][show_net_info:1381] INFO: ########################
09 [BMRT][bmrt_test:769] INFO:==> running network #0, name: network_bmneto, loop: 0
10 [BMRT][bmrt_test:834] INFO:reading input #0, bytesize=150528
11 [BMRT][bmrt_test:987] INFO:reading output #0, bytesize=1000
12 [BMRT][bmrt_test:1018] INFO:net[network_bmneto] stage[0], launch total time is 420 us (npu 327 us, cpu 93 us)
13 [BMRT][bmrt_test:1022] INFO:+++ The network[network_bmneto] stage[0] output_data +++
14 [BMRT][bmrt_test:1038] INFO:==>comparing #0 output ...
15 [BMRT][bmrt_test:1043] INFO:+++ The network[network_bmneto] stage[0] cmp success +++
16 [BMRT][bmrt_test:1063] INFO:load input time(s): 0.000099
17 [BMRT][bmrt_test:1064] INFO:calculate time(s): 0.000422
18 [BMRT][bmrt_test:1065] INFO:get output time(s): 0.000022
19 [BMRT][bmrt_test:1066] INFO:compare time(s): 0.000022
从上面输出可以看到以下信息:
02-08行是bmodel的网络输入输出信息
12行是在TPU上运行的时间,其中TPU用时327us,CPU用时93us。这里CPU用时主要是指在HOST端调用等待时间
15行表示数据运行比对成功
16行是加载数据到NPU的DDR的时间
17行相当于12行的总时间
18行是输出数据取回时间
应用开发
初始化设备及加载bmodel
bm_handle_t handle;
// open device
status = bm_dev_request(&handle, 0);
if (BM_SUCCESS != status) {
return false;
}
// create bmruntime handle and load_bmodel
void *p_bmrt = bmrt_create(handle);
string bmodel_path = "compilation.bmodel";
if(argc > 2) bmodel_path = argv[2];
bmrt_load_bmodel(p_bmrt, bmodel_path.c_str());
前处理
前处理主要是准备数据,可以采用OpenCV等其他数据处理的库,只要最终把数据放到tensor中即可。
注意量化模型要在fp32模型输入的基础上乘以input_scale,然后再转换为int8,才能作为量化模型的输入。
std::string image_name = argv[1];
cv::Mat image = cv::imread(image_name.c_str());
if(image.empty()){
std::cout<<"Failed to read image: "<<image_name<<std::endl;
return -1;
}
auto cv_type = input_dtype == BM_FLOAT32? CV_32FC3: CV_8UC3;
cv::Mat resized;
cv::resize(image, resized, cv::Size(ws, hs), 0, 0, cv::INTER_NEAREST);
resized.convertTo(resized, cv_type,
0.0078125 * input_scale,
-127.5 * 0.0078125 * input_scale);
// Change input memory storage format form Opencv to BMTPU
std::vector<float> input_data(ws*hs*c);
std::vector<cv::Mat> input_channels;
if(cv_type == CV_32FC3) cv_type = CV_32FC1;
if(cv_type == CV_8UC3) cv_type = CV_8UC1;
// map input_data into input_channels
WrapInputLayer(input_channels, input_data.data(), c, hs, ws, cv_type);
cv::split(resized, input_channels);
bm_tensor_t input_tensor;
bmrt_tensor(&input_tensor, p_bmrt, input_dtype, input_shape);
bm_memcpy_s2d(handle, input_tensor.device_mem, input_data.data());
bm_tensor_t output_tensor;
模型推理
模型推理函数是异步的,调用完成后,需要再调用bm_thread_sync进行同步等待。
double start_time = what_time_is_it_now();
bool ret = bmrt_launch_tensor(p_bmrt, net_name.c_str(), &input_tensor, input_num,
&output_tensor, output_num);
if (!ret) {
printf("launch failed!");
exit(-1);
}
// sync, wait for finishing inference or get an undefined output
status = bm_thread_sync(handle);
if (BM_SUCCESS != status) {
printf("thread sync failed!");
exit(-1);
}
后处理
对于分类来说,后处理主要是取top值来得到正确类别。
注意量化模型的输出处理,取出的数据是量化的输出,需要乘上对应的output_scale值才是对应于fp32模型的输出。
size_t size = bmrt_tensor_bytesize(&output_tensor);
std::vector<char> raw_output(size);
// Get output data from device
bm_memcpy_d2s_partial(handle, raw_output.data(), output_tensor.device_mem, size);
// Free output and input device memory
bm_free_device(handle, output_tensor.device_mem);
bm_free_device(handle, input_tensor.device_mem);
// real post-process the output data
// here is to get the top one
auto output_count = bmrt_shape_count(&output_tensor.shape);
auto output_dtype = network_info->output_dtypes[0];
float output_scale = network_info->output_scales[0];
int max_index = 0;
float max_score = -1;
for(int i=0; i<output_count; i++){
float score = 0;
if(output_dtype == BM_FLOAT32) {
score = ((float*)raw_output.data())[i];
} else if(output_dtype == BM_INT8) {
// multiply the output_scale only for quantized model
// for classification, the scale may be useless
score = raw_output[i] * output_scale;
} else {
assert(0);
}
if(score>max_score) {
max_score = score;
max_index = i;
}
}
cout <<"IMAGE "<< image_name
<<" TOP SCORE IS " << max_score
<< " AT " << max_index << endl;
double start_end = what_time_is_it_now();
printf("TOTAL TIME %f s\n", start_end - start_time);
释放设备
// Destroy bmruntime context
bmrt_destroy(p_bmrt);
程序编译脚本
如下是应用的CMake构建脚本具体内容,推荐用find_package来提供环境信息:
cmake_minimum_required(VERSION 3.10)
project(resnet18-classify)
# opencv for preprocess
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
# use libbmrt libbmlib
find_package(libsophon REQUIRED)
include_directories(${LIBSOPHON_INCLUDE_DIRS})
message(STATUS ${LIBSOPHON_LIBS})
aux_source_directory(src SRC_FILES)
add_executable(classify ${SRC_FILES})
target_link_libraries(classify ${OpenCV_LIBS} ${the_libbmlib.so} ${the_libbmrt.so})
install(TARGETS classify DESTINATION bin)
install(FILES
${CMAKE_CURRENT_SOURCE_DIR}/workdir/bmodel/auto-int8/compilation.bmodel
DESTINATION bmodel)
完成构建脚本编写后,开始编译和运行了:
# 此时在resnet18-classify目录下
mkdir build && cd build
cmake ../ -DCMAKE_INSTALL_PREFIX=`pwd`/install && make && make install
此时会在当前生成classify程序,运行命令如下:
./classify ../images/cat.jpg ../workdir/bmodel/fp32/compilation.bmodel
./classify ../images/cat.jpg ../workdir/bmodel/auto-int8/compilation.bmodel
./classify ../images/cat.jpg ../workdir/bmodel/step-int8/compilation.bmodel
打包部署
当尝试不同的bmodel满足业务需求后,可将编译出来的classify程序和bmodel打包,发布到业务系统中。
如之后原始模型有更改,仅需要重新编译bmodel,替换原bmodel即可。
另外, bmodel是与平台无关的,不同平台的相同应用都可以使用同一bmodel。