完整应用移植流程
完整的应用移植过程包括模型编译量化和应用开发部署两部分构成。其中模型编译量化是在tpu-nntc环境中完成的,应用开发部署是在 libsophon 中完成的。
下图展示了移植过程中的基本步骤:
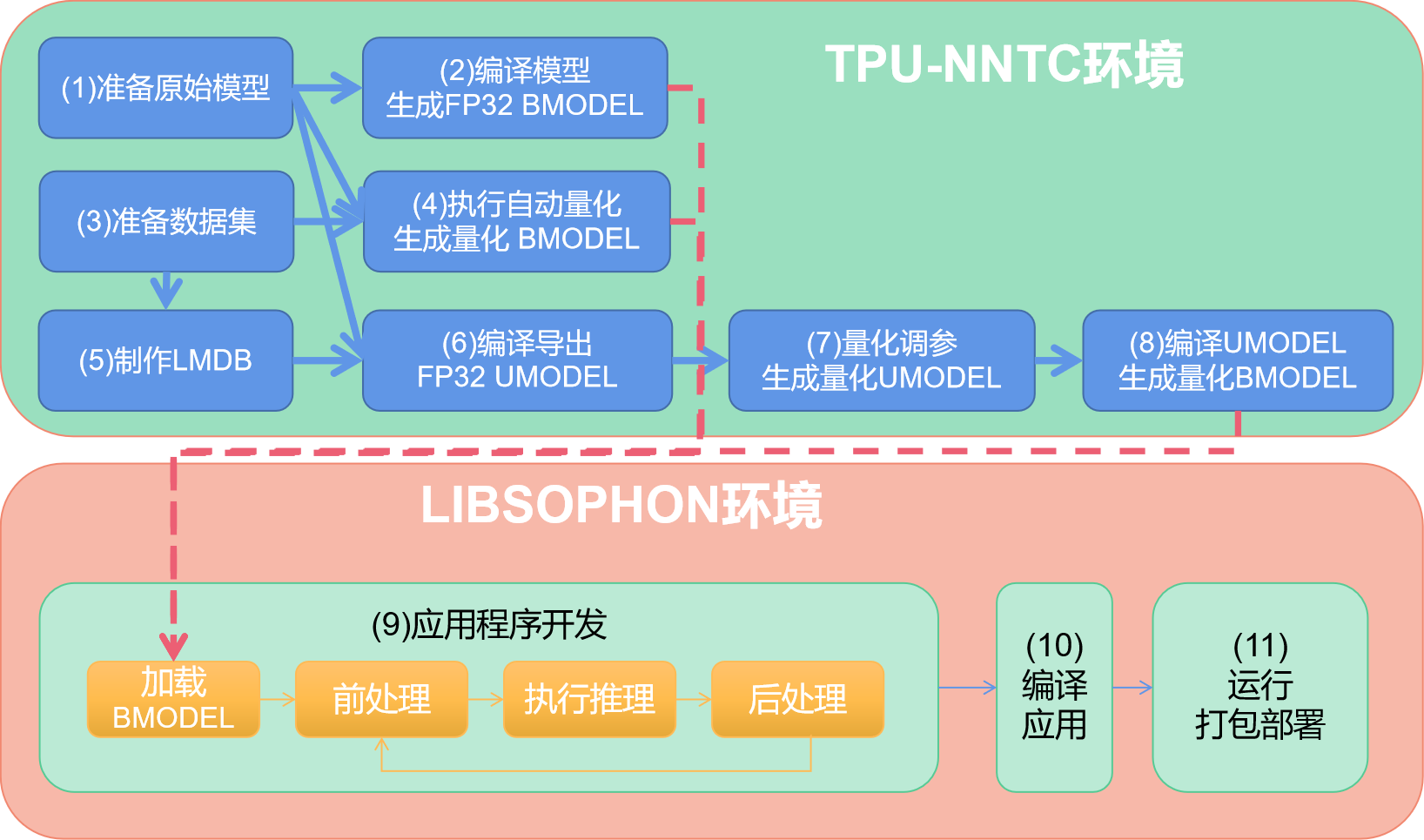
模型编译量化
首先,需要准备离线模型,如onnx、pytorch的trace模型等。 准备好模型后,需要进入tpu-nntc中进行模型编译转换。
FP32 BMODEL生成
针对原始模型,可以利用编译器前端直接将其转换为与原始模型精度一致的FP32 BMODEL,对应于图中步骤(2)。通常该模型用于应用开发与验证业务结果正确性。
量化BMODEL生成
如果FP32不能满足性能需求,需要对模型进行量化, 量化后模型精度会有一定损失,但能充分发挥芯片算力。
首先要准备量化用的输入数据集,如包含输入图片的文件夹。
之后可以进行量化。量化目前提供了两种方式:
自动量化。可以利用数据集和原始模型直接输出量化的BMODEL,对应步骤(4)。优点是步骤简单、参数自动搜索,缺点是时间比较长、性能不一定是最优的。
分步量化。对应于步骤(5)(6)(7)(8)。其中重点是步骤(7)量化调参,需要一定的技巧和经验。
这里,注意区分两个MODEL的概念:
BMODEL是用于设备加载运行的。所有类型的模型转换成BMODEL才能在设备上运行。
UMODEL是用于量化的中间模型。可由原始模型导出FP32的UMODEL,经过量化后会生成INT8的UMODEL,最终也会转换成BMODEL到设备上运行。
应用开发部署
在安装好 libsophon 后,便可以进行应用开发了。
深度学习应用通常会包含加载bmodel,预处理、模型推理、后处理几个部分。注意要点如下:
加载的bmodel是在模型编译生成的;
在开发过程中要注意前处理与量化时的前处理要对齐;
应用编译建议使用CMake编写构建脚本。
应用部署打包根据业务需要,安装对应平台的 libsophon 即可。