Complete implanting application process
A complete implanting application process includes model compilation quantization and application development & deployment. To be specific, the former is finished under tpu-nntc environment while the latter in libsophon.
The figure below shows the basic steps of implanting:
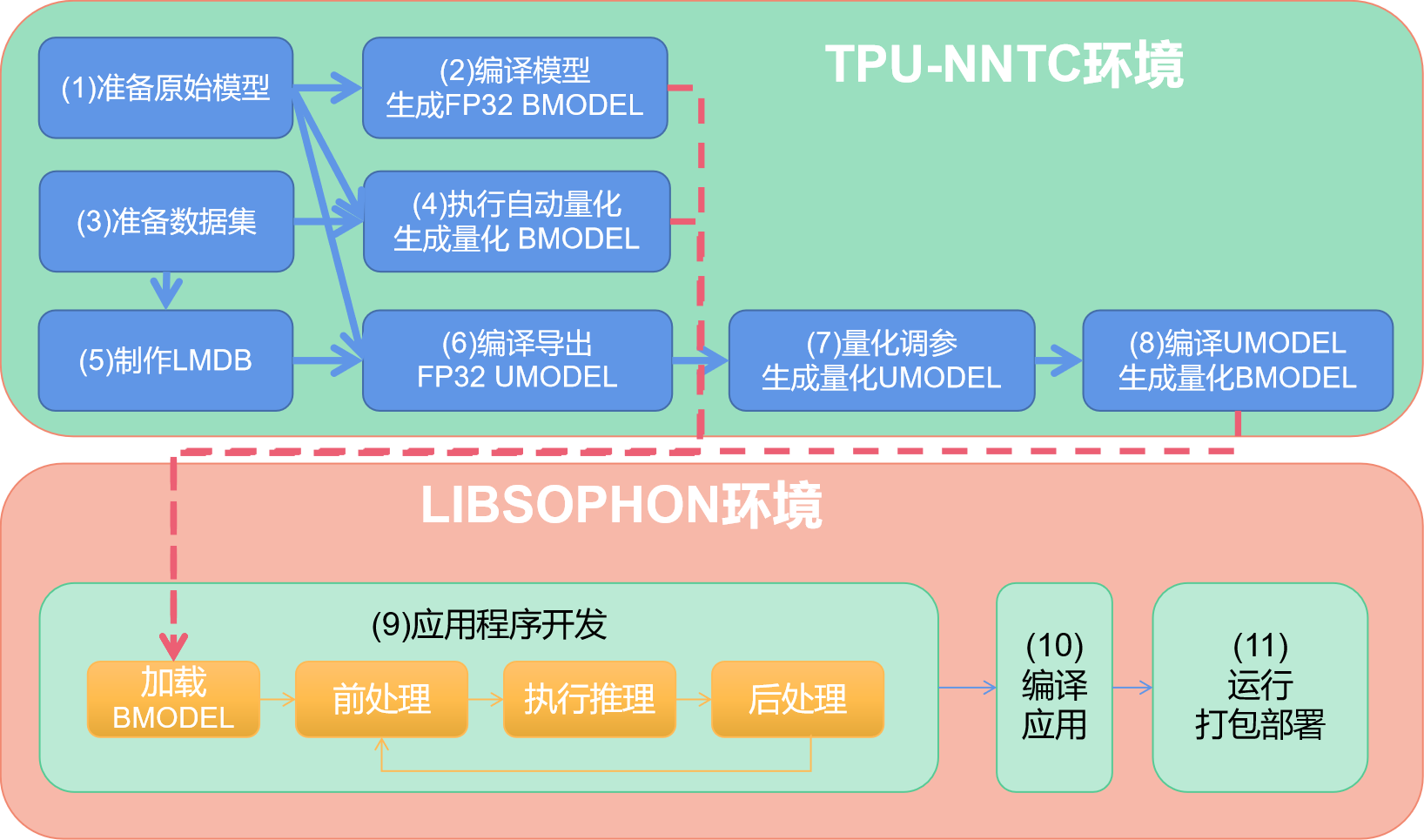
Model compilation quantization
First of all, prepare offline models, such as trace models of onnx and pytorch. After finishing preparing models, enter tpu-nntc for model compilation conversion.
FP32 BMODELgeneration
The original model can be directly converted into FP32 BMODEL whose precision is in consistency with the original model in virtue of the compiler front end. This step is corresponding to Step (2) in the figure. In general, the model is used for application development and verification of business result correctness.
Generation of quantization BMODEL
If FP32 cannot satisfy performance requirements, quantify the model. The precision of quantified model will be certainly lost but the chip hashrate can still be exerted fully.
First of all, prepare input dataset used for quantization, such as folders containing input image.
Then carry out quantization. Two quantization modes are available at present:
Automatic quantization. Quantized BMODEL can be output directly in virtue of dataset and original model, which is corresponding to Step (4). Its advantages include simple steps and automatic parameter search but the disadvantages are long time period and failure in ensuring the best performance.
Step-based quantization. Corresponding to Step (5)(6)(7) and (8). In particular, Step (7) is the main step, which covers quantization parameter adjustment. This step entails certain skills and experience.
Special attention should be paid to distinguishing the concepts of the two MODELS:
BMODEL is used for loaded running of equipment. The models of all types cannot run on equipment before they are converted into BMODEL.
UMODEL is the intermediate model used for quantization. FP32 UMODEL exported from the original model can generate INT8 UMODEL after quantization and is finally converted into BMODEL that will run on equipment.
Application development & deployment
Application development can be carried out after libsophon installation.
In general, in-depth learning application includes loaded bmodel, pre-processing, model reasoning and post-processing respectively. Attentions:
Loaded bmodel is generated after compilation in model;
Ensure the pre-processing aligns with the pre-processing in course of quantization during development.
Cmake is recommended to prepare and build script for application compilation
libsophon of the corresponding platform should be installed for application deployment packaging according to the specific business demands.