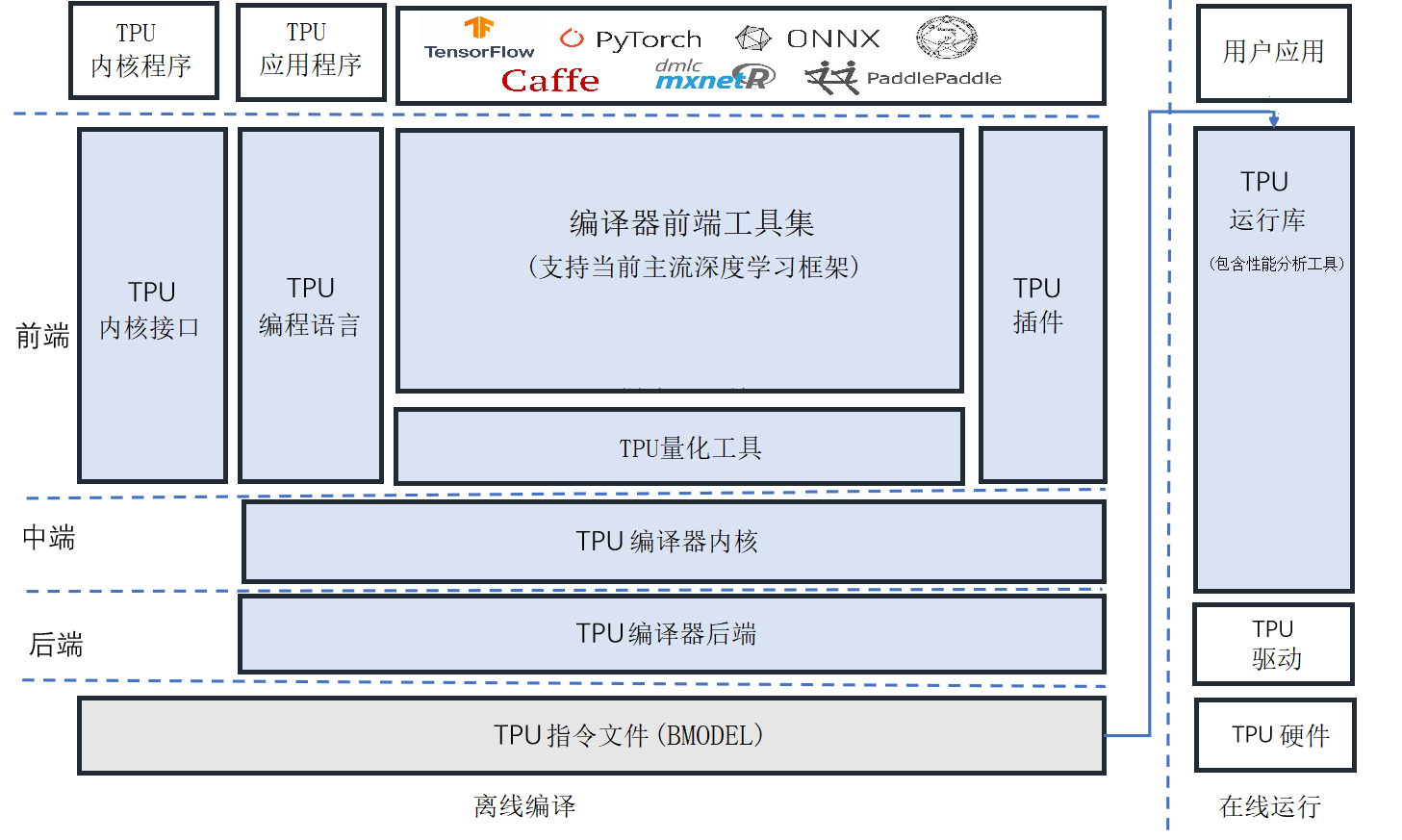
NNToolChain 整体架构
SOPHONSDK的NNToolchain是算能基于其自主研发的AI芯片,所定制的深度学习工具链,涵盖了神经网络推理阶段所需的模型优化、高效运行时支持等能力,为深度学习应用开发和部署提供易用、高效的全栈式解决方案。
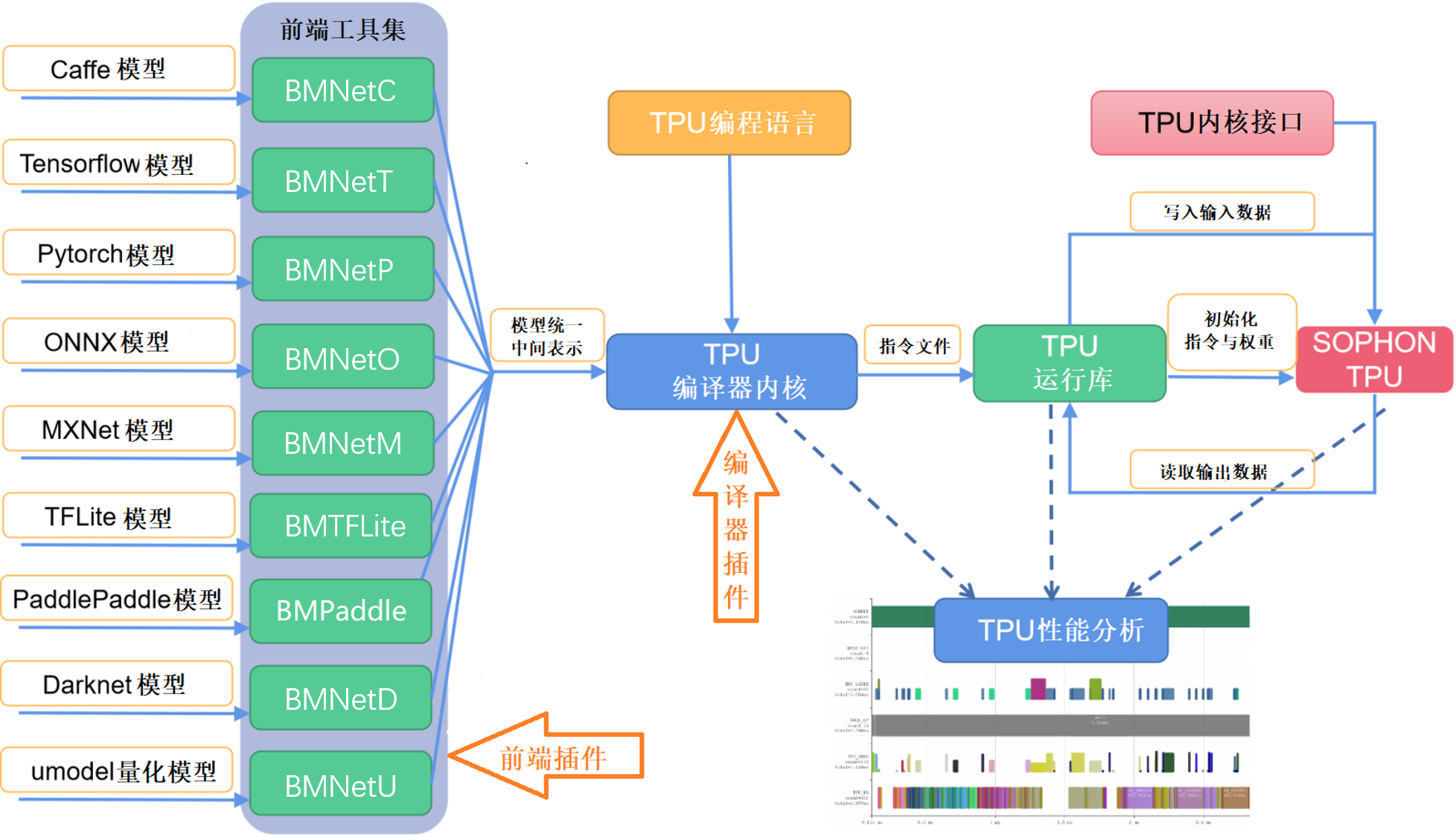
NNToolchain整体架构如下图所示,由Compiler和Runtime(图中左右)两部分组成。Compiler负责对各种主流深度神经网络模型(如Caffe model、Tensorflow model等)进行编译和优化。Runtime向下屏蔽底层硬件实现细节,驱动TPU芯片,向上为应用程序提供统一的可编程接口,既提供神经网络推理功能,又提供对DNN和CV算法的加速。
NNToolChain工作流程请见下图。首先,Compiler将主流框架模型转换成TPU能够识别的模型格式——bmodel。然后,Runtime读取bmodel,将数据写入TPU供神经网络推理,随后读回TPU处理结果。此外,还允许TPU编程语言构建自定义上层算子和网络,TPU内核接口允许在TPU设备上直接编程。利用TPU性能分析工具还可以对模型进行性能剖析。利用相关的插件机制允许用户扩展前端与优化Pass。