7. Calibration
7.1. 总体介绍
所谓校准,就是用用真实场景数据来调校出恰当的量化参数,为何需要校准?当我们对激活进行非对称量化时, 需要预先知道其总体的动态范围,即minmax值, 对激活进行对称量化时,需要预先使用合适的量化门限算法在激活总体数据分布 的基础上计算得到其量化门限,而一般训练输出的模型是不带有激活这些数据统计 信息的,因此这两者都要依赖于在一个微型的训练集子集上进行推理,收集各个 输入的各层输出激活,汇总得到总体minmax及数据点分布直方图,并根据KLD等 算法得到合适的对称量化门限threshold,最后会启用auto-tune算法使用各int8层 输出激活与fp32激活的欧式距离来对这些该int8层的输入激活量化门限进行调优; 上述过程整合在一起,统一执行,最后将各个op的优化后的threshold和min/max值 输出到一个量化参数文本文件中,后续``model_deploy.py``时就可使用这个参数 文件来进行后续的int8量化,总体过程如(量化总体过程)图

图 7.1 量化总体过程
如下图(量化参数文件样例)为校准最终输出的量化参数文件
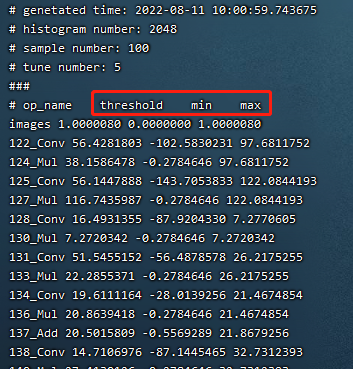
图 7.2 量化参数文件样例
7.2. 校准数据筛选及预处理
7.2.1. 筛选原则
在训练集中挑选约100~200张覆盖各个典型场景风格的图片来进行校准,采用类似训练数据清洗的方式,要排除掉一些异常样例;
7.2.2. 输入格式及预处理
格式 |
描述 |
|---|---|
原始图片 |
对于CNN类图片输入网络,支持直接输入图片,要求在前面生成mlir文件时, model_transform.py命令要指定和训练时完全一致的图片预处理参数 |
npz或npy文件 |
对于非图片输入或图片预处理类型较复杂tpu-mlir暂不支持的情形,建议额外编写 脚本将完成预处理后的输入数据保存到npz/npy文件中(npz文件是多个输入tensor 按字典的方式打包在一起,npy文件是1个文件包含1个tensor), run_calibration.py支持直接导入npz/npy文件 |
上面2种格式,在调用run_calibration.py调用mlir文件进行推理时,就无需再指定校准图片的预处理参数了
方式 |
描述 |
|---|---|
–dataset |
对于单输入网络,放置输入的各个图片或已预处理的输入npy/npz文件(无顺序要求);对于多输入网络, 放置各个样本的已预处理的npz文件 |
–data_list |
将各个样本的图片文件地址,或者npz文件地址,或者npy文件地址,一行放一个样本, 放置在文本文件中,若网络有多个输入文件,文件间通过逗号分割(注意npz文件应该只有1个输入地址) |
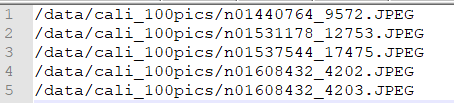
图 7.3 data_list要求的格式样例
7.3. 算法实现
7.3.1. kld算法
tpu-mlir实现的kld算法参考tensorRT的实现,本质上是将abs(fp32_tensor)这个波形(用2048个fp32 bin的直方图表示),截掉一些高位 的离群点后(截取的位置固定在128bin、256bin…一直到2048bin)得到fp32参考概率分布P,这个fp32波形 若用128个等级的int8类型来表达,将相邻的多个bin(比如256bin是相邻的2个fp32 bin)合并成1个int8值等级计算分布 概率后,再扩展到相同的bin数以保证和P具有相同的长度,最终得到量化后int8值的概率分布Q,计算P和Q的KL散度, 在一个循环中,分别对128bin、256bin、…、2048bin这些截取位置计算KL散度,找出具有最小散度的截取位置, 这说明在这里截取,能用int8这128个量化等级最好的模拟fp32的概率分布,故量化门限设在这里是最合适的。kld算法实现伪码 如下所示:
1the pseudocode of computing int8 quantize threshold by kld:
2 Prepare fp32 histogram H with 2048 bins
3 compute the absmax of fp32 value
4
5 for i in range(128,2048,128):
6 Outliers_num=sum(bin[i], bin[i+1],…, bin[2047])
7 Fp32_distribution=[bin[0], bin[1],…, bin[i-1]+Outliers_num]
8 Fp32_distribution/= sum(Fp32_distribution)
9
10 int8_distribution = quantize [bin[0], bin[1],…, bin[i]] into 128 quant level
11 expand int8_distribution to i bins
12 int8_distribution /= sum(int8_distribution)
13 kld[i] = KLD(Fp32_distribution, int8_distribution)
14 end for
15
16 find i which kld[i] is minimal
17 int8 quantize threshold = (i + 0.5)*fp32 absmax/2048
7.3.2. auto-tune算法
从KLD算法的实际表现来看,其候选门限相对较粗,也没有考虑到不同业务的特性,比如:对于目标检测、关键点检测等业务,tensor的离群点 可能对最终的结果的表现更加重要,此时要求量化门限更大,以避免对这些离群点进行饱和而影响到这些分布 特征的表达;另外,KLD算法是基于量化后int8概率分布与fp32概率分布的相似性来计算量化门限,而评估波形相似性的方法 还有其他比如欧式距离、cos相似度等方法,这些度量方法不用考虑粗略的截取门限直接来评估tensor数值分布相似性,很多时候 能有更好的表现;因此,在高效的KLD量化门限的基础上,tpu-mlir提出了auto-tune算法对这些激活的量化门限基于欧式距离 度量进行微调,从而保证其int8量化具有更好的精度表现;
实现方案:首先统一对网络中带权重layer的权重进行伪量化,即从fp32量化为int8,再反量化为fp32,引入量化误差;然后 逐个对op的输入激活量化门限进行调优:在初始KLD量化门限和激活的最大绝对值之间,均匀选择10个候选值,用这些候选者 对fp32参考激活值进行量化加扰,引入量化误差,然后输入op进行fp32计算,将输出的结果与fp32参考激活进行欧式距离计算, 选择10个候选值中具有最小欧式距离的值作为调优门限;对于1个op输出连接到后面多个分支的情形,多个分支分别按上述方法 计算量化门限,然后取其中较大者,比如(auto-tune调优实现方案)图中layer1的输出会分别针对layer2、layer3调节一次,两次调节独立进行, 根据实验证明,取最大值能兼顾两者;
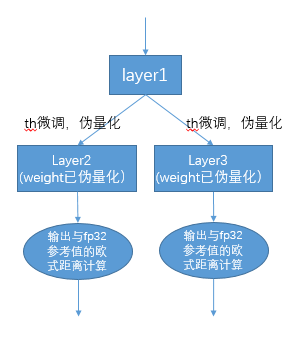
图 7.4 auto-tune调优实现方案
7.4. 示例-yolov5s校准
在tpu-mlir的docker环境中,在tpu-mlir目录执行source envsetup.sh初始化环境后,任意新建目录进入执行如下命令可以完成对yolov5s的校准过程:
1$ model_transform.py \
2 --model_name yolov5s \
3 --model_def ${REGRESSION_PATH}/model/yolov5s.onnx \
4 --input_shapes [[1,3,640,640]] \
5 --keep_aspect_ratio \ #keep_aspect_ratio、mean、scale、pixel_format均为预处理参数
6 --mean 0.0,0.0,0.0 \
7 --scale 0.0039216,0.0039216,0.0039216 \
8 --pixel_format rgb \
9 --output_names 350,498,646 \
10 --test_input ${REGRESSION_PATH}/image/dog.jpg \
11 --test_result yolov5s_top_outputs.npz \
12 --mlir yolov5s.mlir
13
14$ run_calibration.py yolov5s.mlir \
15 --dataset $REGRESSION_PATH/dataset/COCO2017 \
16 --input_num 100 \
17 --tune_num 10 \
18 -o yolov5s_cali_table
执行结果如下图(yolov5s_cali校准结果)所示
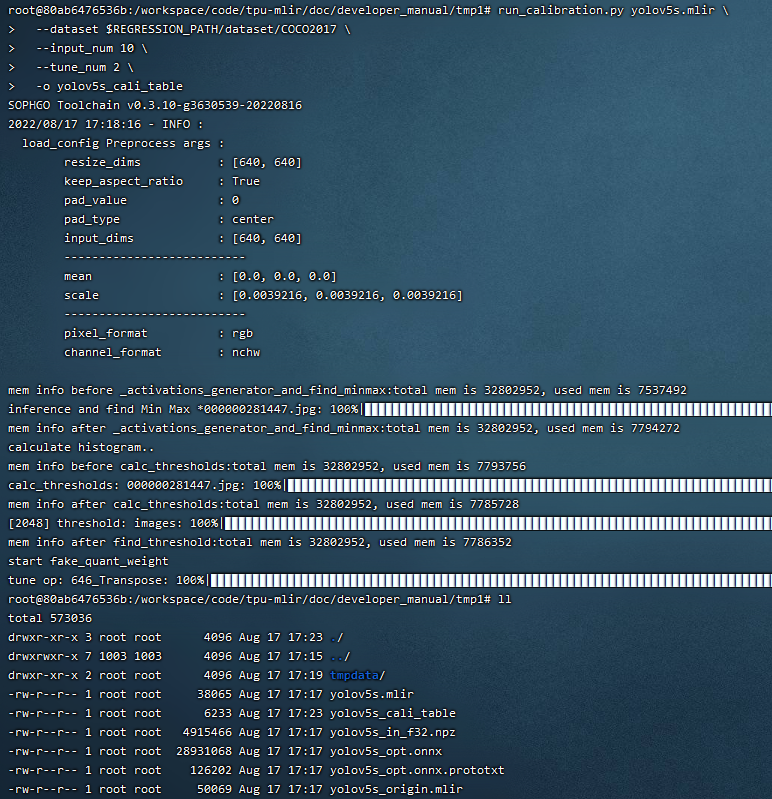
图 7.5 yolov5s_cali校准结果